
Stop Wasting Time: Here’s How to Prepare Data for AI the Smart Way
Everything you need to know to transform messy, siloed data into structured, AI-ready gold—with real-world examples and automation tips.

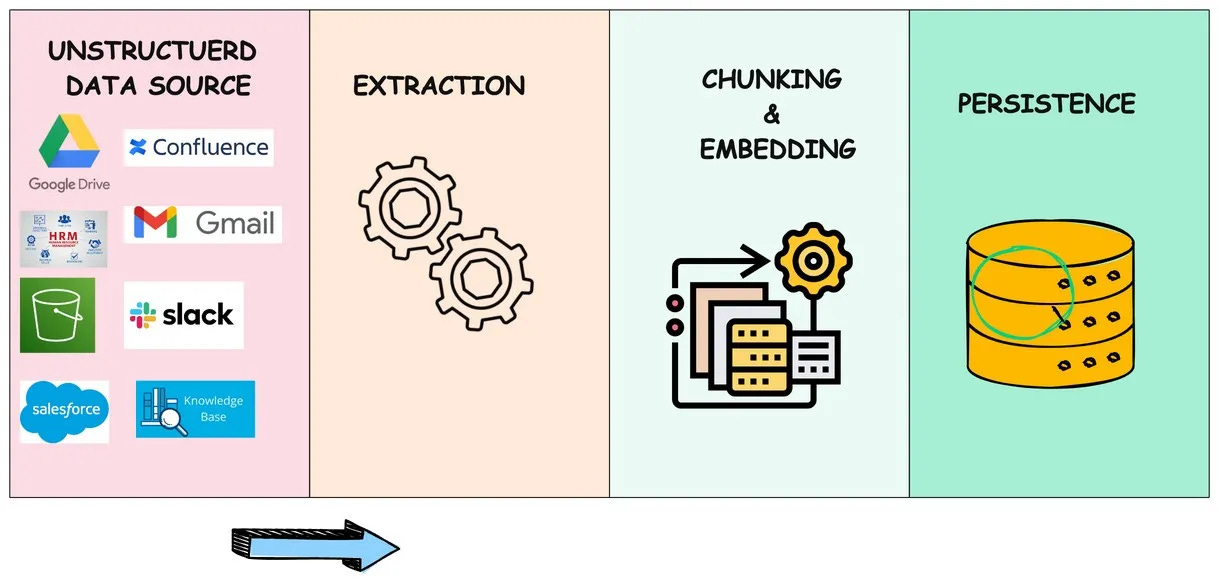
Before you start training GenAI using your company’s data, you need to prepare it. Following this step-by-step process should provide clear guidance and ease successful data preparation. Many believe that manually preparing data is the only way to ensure accuracy. This simply isn’t true. Automated tools, like Unstructured AI, can clean, format, and transform data faster while reducing the risk of human error. It allows data scientists to focus on model development, rather than tedious data prep tasks.
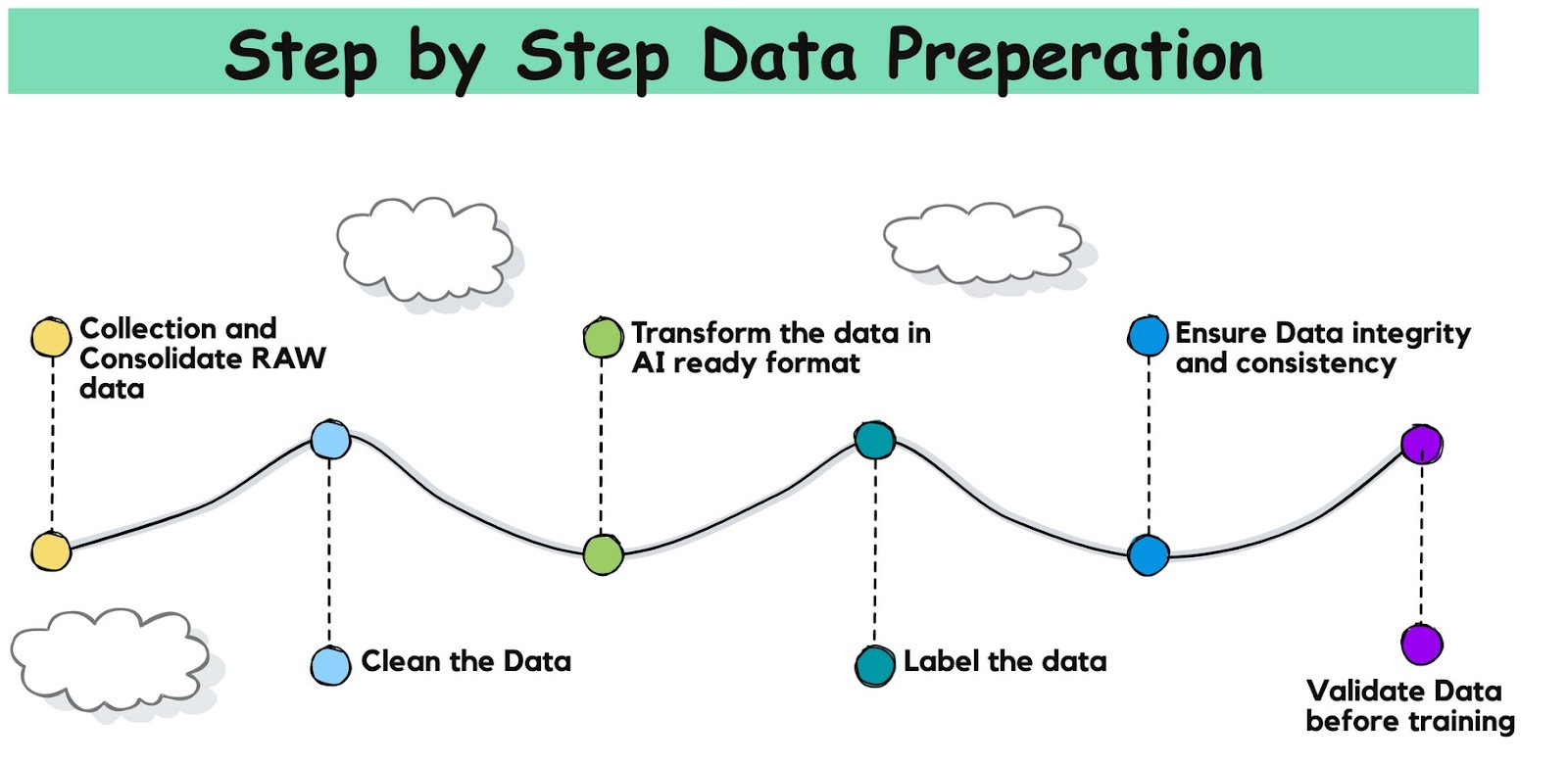
Step #1: Collect and Consolidate Raw Data
The very first and primary step is data collection from all relevant internal and external sources. This can include:
structured data from databases,
unstructured data from emails, or
sensitive data stored in data warehouses.
Often, data is scattered across different tools like google drive, jira , confluence, CRMs — offices, data centers, factories, or creative hubs. When your data is siloed across multiple sites like that, it prevents AI from reaching its full potential. For AI services to operate effectively, data must be centralized.
To maximize AI effectiveness, consolidate all data into a single location. To collect data, you may first need to extract it from the documents it’s buried in.
Reference read on data cleaning https://www.databytego.com/p/the-rise-of-unstructured-data-etl
Take PDFs as an example.
PDFs are often filled with text, images, and even tables. That’s why our first step is typically to extract all that information by using tools that grab the plain text; but also pull out images, figures, and tables.
For example, if we’re working with an invoice in a PDF format, we may extract:
The invoice number, date, and total (text)
A company logo (image)
An itemized breakdown (table).
Step #2: Clean the Data
The next step should be data cleaning. It involves:
identifying and fixing errors,
removing duplicates,
handling missing values,
ensuring data consistency.
For more details on the data cleaning - please referen to the blog on data clearing for RAG system https://www.databytego.com/p/aillm-series-building-a-smarter-data-510?utm_source=publication-search
This is arguably the most time-consuming process. If you fail to clean data correctly, your model’s performance will suffer.
Step #3: Transform Data Into AI-Ready Formats
After cleaning, analyze your data with exploratory data analysis (EDA) to uncover trends, distributions, and patterns. Transform raw data into formats suitable for AI by:
Converting Formats: Change categorical values (e.g., "Male/Female" to 0/1).
Standardizing Units: Ensure consistent measurements (e.g., all distances in kilometers).
Structuring Unstructured Data: Use natural language processing (NLP) to break legal documents into tokenized sentences or classify paragraphs like "Terms and Conditions" or "Client Details."
Example: Processing invoices into structured datasets:
Header Info: Invoice number, date, and client name.
Tables: Item names, prices, quantities, and totals.
Images: Company logos or signatures.
This structured data can be stored in CSV files or databases for efficient analysis.
Step #4: Label the Data
Proper labeling enables supervised machine learning to identify patterns. Start by defining clear labels tailored to your business needs.

Image Data: Tag objects in images, like "cat," "dog," or "car."
Text Data: Categorize documents by topic, such as "legal," "financial," or "healthcare."
Example: A healthcare company labels patient records with categories like "diabetes," "hypertension," or "routine checkup" to train an AI model for diagnosis prediction.
Step #5: Address Dimensionality and Reduce Data
Large datasets often have irrelevant variables that complicate training and lead to overfitting. Use dimensionality reduction techniques like PCA (Principal Component Analysis) or feature selection.let’s take an example. In insurance, filter impactful factors like claim history or credit score while removing less relevant ones, such as a customer’s preferred contact method, to streamline the dataset and enhance model performance.
Step #6: Ensure Data Integration and Consistency
Combine all data sources into a unified, consistent format to avoid errors or fragmentation. For example, In e-commerce, integrate sales data from multiple platforms (e.g., website, mobile app, and physical store) into a single dataset with standardized formats for customer ID, purchase date, and transaction amount.
Step #7: Validate Data Before Training
Validate your data to catch any lingering errors or inconsistencies and ensure it’s formatted correctly for machine learning algorithms. Proper validation guarantees a solid foundation for building accurate AI models.
checks to ensure data is error-free and formatted correctly for machine learning algorithms.
Data prep isn’t busywork—it’s the foundation of good AI.
Before jumping into model training, taking the time to consolidate, clean, transform, and label your data ensures a solid foundation. Poor data leads to poor models. But with smart automation tools like Unstructured, NLP techniques, and consistent validation practices, you can prepare datasets at scale without sacrificing quality.
Whether you’re working with invoices, health records, or legal documents, structured data is your biggest asset in AI development. Follow these steps, and you’ll not only save time—you’ll also ensure your AI systems are accurate, explainable, and trustworthy.
References
DataByteGo. (2024). The Rise of Unstructured Data ETL. https://www.databytego.com/p/the-rise-of-unstructured-data-etl
DataByteGo. (2024). Building a Smarter Data Cleaning System for RAG. https://www.databytego.com/p/aillm-series-building-a-smarter-data-510
Previous articles :

![[AI/LLM Series] Building a smarter data pipeline for LLM & RAG: The key to enhanced accuracy and performance[part-2]](https://substackcdn.com/image/fetch/$s_!jaF_!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F31f96679-3b4c-4cc3-95e7-f2c29c6c2111_1219x588.jpeg)
