The Cost of Dirty Data- How AI Projects Pay the Price
The High Stakes of Dirty Data: How Organizations Lose $12.9 Million Annually, Face 20% Productivity Declines, and See Costs Soar by 30%—and What It Means for AI Success
Data is the foundation of enterprises, larger or small. Data is being used in every decision, the more critical and important the decision is, the more important the data and the quality of data becomes.
It’s not any different for Artificial intelligence. Data is the backbone for any AI application. It has a direct relationship on how the AI or machine learning model (MLM) or fine-tuning Generative AI systems is going to perform.
If you are planning to adopt AI for your enterprise or application, it’s really important that you understand that data directly impacts AI models' accuracy, efficiency, and performance.
Source: Internet
Key Takeaways
Data preparation is the key to success: Preparing data for AI is essential to ensure accurate insights and reliable performance( raw, unstructured data can lead to errors and inefficiencies )
Data goals are important: Understand the goals of data preparation - Is it quality, quantity, and completeness.
ETL(Extract, Transform, Load) → Data preparation includes collecting, cleaning, transforming, and labeling data while consolidating it from multiple locations for better accessibility.
Build the enterprise Data journey: What the data journey is going to look like once the model is trained but new data is coming regularly.
For any AI initiatives, integrity of the data and information is the key. Yet, most of the organization struggle with “Dirty Data” - information that is incomplete, inconsistent, or inaccurate—which can significantly undermine or even Kill AI projects.
Let's take a snapshot of Data trust within organizations.
source:snaplogic
Impact “$$$” of Dirty Data
What do industry leaders have to say about this?
Veda Bawo, Director of Data Governance at Raymond James, emphasizes, "You can have all of the fancy tools, but if [your] data quality is not good, you're nowhere." MIT Sloan School of Management
Dean Abbott, Co-founder and Chief Data Scientist at SmarterHQ, notes, "No data is clean, but most is useful," highlighting the importance of data cleaning in the analysis process. CareerFoundry
A report from Gartner indicates that poor data quality costs organizations an average of $12.9 million per year, underscoring the financial impact of dirty data. Esri
Let’s dig in..
What is Dirty Data?
Dirty data refers to information that is flawed, either due to inaccuracy, incompleteness, inconsistency, or redundancy, which reduces its usage and reliability for decision-making or analytical purposes. When applied to AI and machine learning models, dirty data can distort training outcomes, leading to incorrect or biased predictions. This leads to low performance of the AI models.
To Simplify it: Dirty data is like messy or wrong information that doesn't make sense or is missing parts. This makes it hard to use for figuring things out or solving problems. If AI or computer programs use messy data to learn, they can get confused and make wrong guesses or unfair decisions, which makes them work poorly.
Below is a detailed look at different types of dirty data, their sources, and examples.
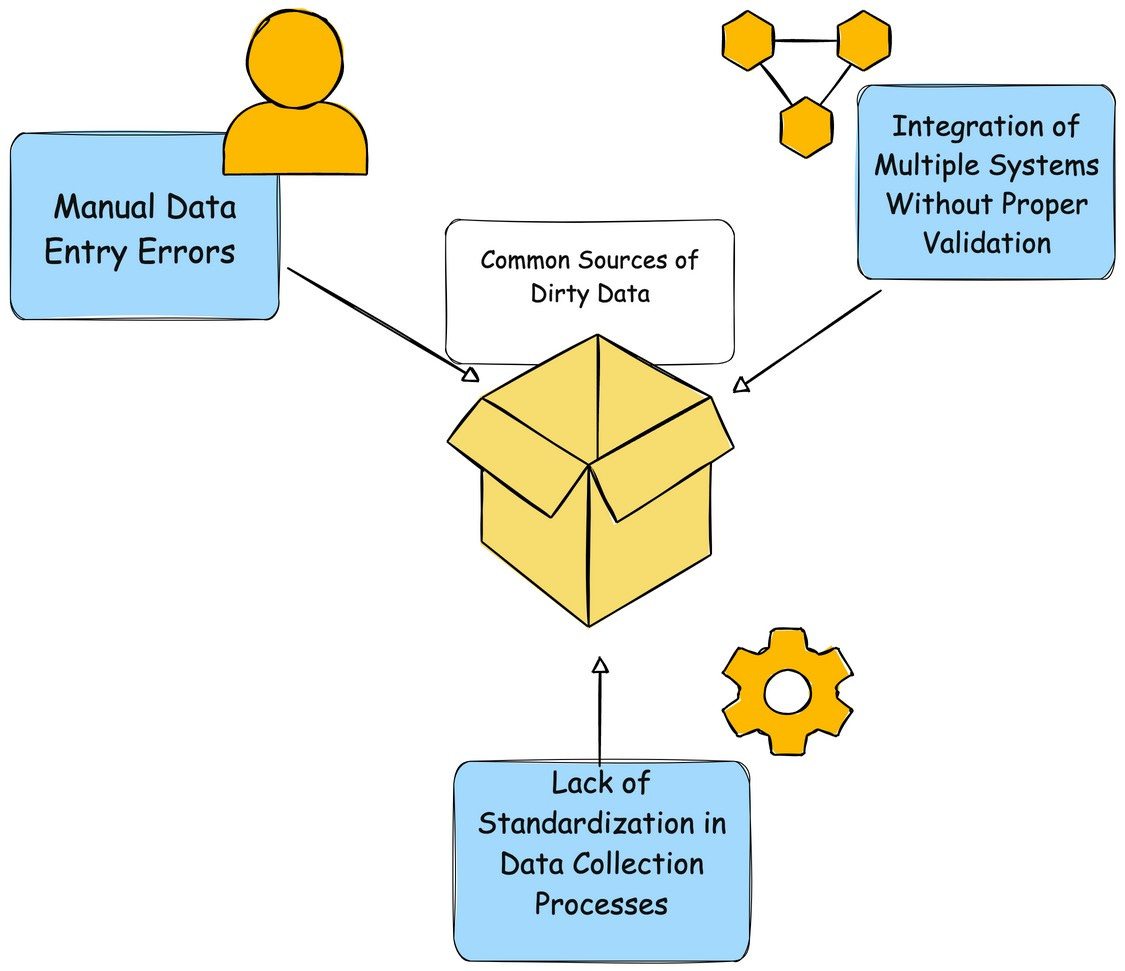
Common Sources of Dirty Data
Manual Data Entry Errors Human input errors are among the most common causes of dirty data. For example:
Typographical mistakes.
Incorrect field usage (e.g., entering an email address in a phone number field).
Integration of Multiple Systems Without Proper Validation When datasets from disparate systems are merged, inconsistencies and redundancies often arise:
Mismatched field mappings during system migrations.
Conflicts between legacy systems and modern platforms.
Lack of Standardization in Data Collection Processes Inconsistent protocols across departments or teams lead to variations in data quality. Examples include:
Different teams using varied templates for data input.
Absence of defined protocols for capturing or formatting information.
The strength of AI depends on the quality of data
The quality of the data used to train AI systems is crucial to their reliability. If the data is incomplete or inaccurate, it can lead to significant problems:
Bias and discrimination: AI systems trained on biased data can reproduce and amplify these biases in their results. This can lead to discrimination against certain groups of people.
Incorrect decisions: If the data contains erroneous information, AI systems may make incorrect decisions. This can have serious consequences, particularly in areas such as healthcare, finance, and law enforcement.
Security risks: Erroneous data can also be exploited by malicious actors to manipulate AI systems. This can lead to security risks, such as hacking or the spread of misinformation.
This means that the data should be:
Complete: It should contain all relevant information.
Accurate: It should be free from inaccuracies.
Representative: It should reflect the real world in which the AI system will be used.
Objective: It should be free from biases and discrimination.
Why Is Preparing Data for AI Important?
AI thrives on high-quality data—the better prepared the data, the better the results. Raw data often contains errors, inconsistencies, and gaps that could severely impact the AI model's performance.
Unstructured data is especially problematic, as AI models have a harder time processing it than structured data.
Proper data preparation for Generative AI reduces these issues, ensuring accurate insights and better model performance. While the specific percentage may vary, most surveys agree that data engineers spend between 40 and 80% of their time on data preparation activities.
Poorly prepared data can lead to faulty results or wasted resources. For example, missing values, data inconsistencies, and irrelevant data points all reduce the effectiveness of machine learning algorithms. That is why this preliminary step is crucial for your AI implementation.
The Goal of Preparing Data for AI
When preparing data for AI, the primary goals are:
Quality: Data must be accurate, complete, and relevant.
Quantity: AI requires large datasets to build reliable and scalable models.
Completeness: Missing data points must be handled to avoid inaccurate outcomes.
An additional goal can be converting raw, unorganized (or unstructured) data into a clean, structured format that AI models can actually use.
With these goals in mind, let's explore the practical steps.
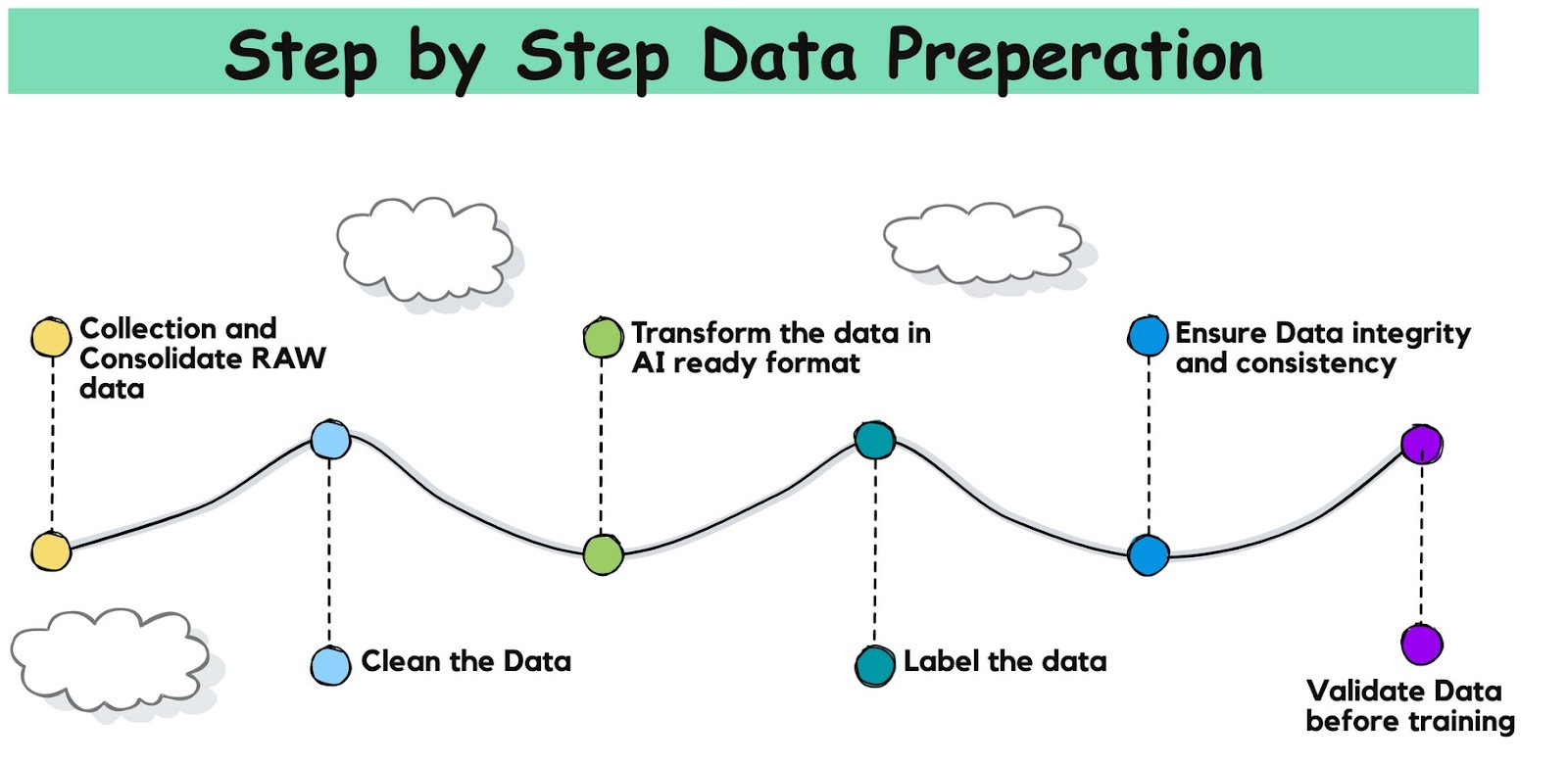
How to Prepare Data for AI: Step-by-Step Instructions
Before you start training GenAI using your company’s data, you need to prepare it. Following this step-by-step process should provide clear guidance and ease successful data preparation. Many believe that manually preparing data is the only way to ensure accuracy. This simply isn’t true. Automated tools, like Unstructured AI, can clean, format, and transform data faster while reducing the risk of human error. It allows data scientists to focus on model development, rather than tedious data prep tasks.
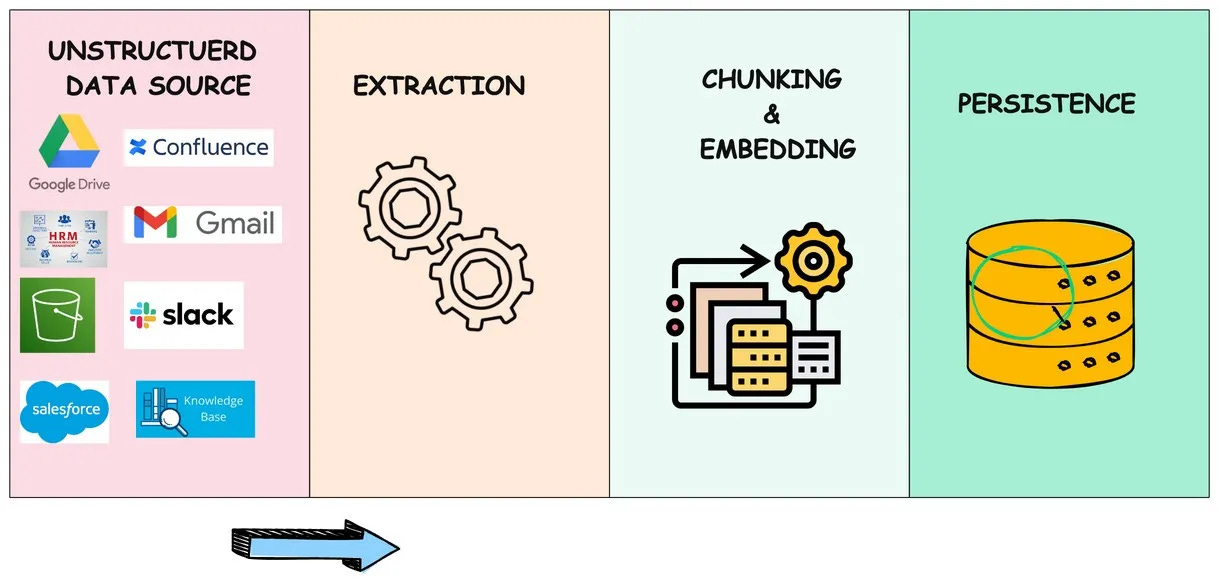
Step #1: Collect and Consolidate Raw Data
The very first and primary step is data collection from all relevant internal and external sources. This can include:
structured data from databases,
unstructured data from emails, or
sensitive data stored in data warehouses.
Often, data is scattered across different tools like google drive, jira , confluence, CRMs — offices, data centers, factories, or creative hubs. When your data is siloed across multiple sites like that, it prevents AI from reaching its full potential. For AI services to operate effectively, data must be centralized.
To maximize AI effectiveness, consolidate all data into a single location. To collect data, you may first need to extract it from the documents it’s buried in.
PDFs are often filled with text, images, and even tables. That’s why our first step is typically to extract all that information by using tools that grab the plain text; but also pull out images, figures, and tables.
For example, if we’re working with an invoice in a PDF format, we may extract:
The invoice number, date, and total (text)
A company logo (image)
An itemized breakdown (table).
Step #2: Clean the Data
The next step should be data cleaning. It involves:
This is arguably the most time-consuming process. If you fail to clean data correctly, your model’s performance will suffer.
Step #3: Transform Data Into AI-Ready Formats
After cleaning, analyze your data with exploratory data analysis (EDA) to uncover trends, distributions, and patterns. Transform raw data into formats suitable for AI by:
Converting Formats: Change categorical values (e.g., "Male/Female" to 0/1).
Standardizing Units: Ensure consistent measurements (e.g., all distances in kilometers).
Structuring Unstructured Data: Use natural language processing (NLP) to break legal documents into tokenized sentences or classify paragraphs like "Terms and Conditions" or "Client Details."
Example: Processing invoices into structured datasets:
Header Info: Invoice number, date, and client name.
Tables: Item names, prices, quantities, and totals.
Images: Company logos or signatures.
This structured data can be stored in CSV files or databases for efficient analysis.
Step #4: Label the Data
Proper labeling enables supervised machine learning to identify patterns. Start by defining clear labels tailored to your business needs.
Image Data: Tag objects in images, like "cat," "dog," or "car."
Text Data: Categorize documents by topic, such as "legal," "financial," or "healthcare."
Example: A healthcare company labels patient records with categories like "diabetes," "hypertension," or "routine checkup" to train an AI model for diagnosis prediction.
Step #5: Address Dimensionality and Reduce Data
Large datasets often have irrelevant variables that complicate training and lead to overfitting. Use dimensionality reduction techniques like PCA (Principal Component Analysis) or feature selection.let’s take an example. In insurance, filter impactful factors like claim history or credit score while removing less relevant ones, such as a customer’s preferred contact method, to streamline the dataset and enhance model performance.
Step #6: Ensure Data Integration and Consistency
Combine all data sources into a unified, consistent format to avoid errors or fragmentation. For example, In e-commerce, integrate sales data from multiple platforms (e.g., website, mobile app, and physical store) into a single dataset with standardized formats for customer ID, purchase date, and transaction amount.
Step #7: Validate Data Before Training
Validate your data to catch any lingering errors or inconsistencies and ensure it’s formatted correctly for machine learning algorithms. Proper validation guarantees a solid foundation for building accurate AI models.
checks to ensure data is error-free and formatted correctly for machine learning algorithms.
Common Myths About Data Preparation for AI
Myth #1: Sharing Data with AI Hosts Always Compromises Security
A major concern when preparing data for AI is deciding where to deploy your AI infrastructure. A widespread misconception is that sharing data with third-party AI hosts inherently leads to security vulnerabilities. While risks exist, their severity depends on the hosting method and the safeguards in place.
For companies operating in highly regulated industries like finance or healthcare, the safest option is to deploy AI solutions on self-managed infrastructure, such as on-premise servers or virtual private clouds (VPCs). This ensures sensitive data remains within your control, significantly reducing exposure to potential vulnerabilities.
Myth #2: You Need a Perfect Dataset
The idea that a dataset must be flawless to train effective AI models is a common myth. In reality, no dataset is ever truly perfect, and striving for perfection can lead to unnecessary delays and wasted resources. What truly matters is having a dataset that is sufficiently clean and structured to produce reliable and actionable results.
The focus should always be on continuous improvement rather than chasing perfection. Iteratively refining your dataset as your AI solution evolves will often yield better outcomes than spending excessive time attempting to make it flawless from the start.
Myth #3: Bigger Datasets Are Always Better
When it comes to AI, bigger doesn’t always mean better. While having more data can be beneficial, sheer volume alone won’t improve your models—especially if the data is noisy, incomplete, or irrelevant. Large datasets of poor quality can actually harm your model’s performance, leading to inaccurate results and wasted effort.
The key is to prioritize high-quality, relevant, and well-structured data over quantity. Clean and accurate datasets enable your models to learn effectively and deliver reliable outcomes.
Rather than collecting data indiscriminately, invest in refining and curating datasets that truly add value to your AI models. Quality will always outweigh quantity when it comes to building effective AI solutions.
Myth #4: Manual Data Preparation is Better Than Automated Tools
While manual data preparation can offer control, it’s often slow, error-prone, and inefficient for large datasets. Automated tools excel at repetitive tasks like cleaning, normalizing, and labeling data, ensuring consistency and scalability with greater speed and accuracy. While manual intervention may be needed for specific edge cases, leveraging automation saves time and effort, allowing teams to focus on strategic priorities while ensuring reliable, AI-ready data.
Frequent Data Preparation Challenges to Anticipate
Preparing data for AI is essential but not without its hurdles. Recognizing and addressing these challenges early can significantly impact the success of your AI initiatives. Here are some common challenges with detailed, practical examples:
Data Quality Issues: Poor-quality data, such as duplicate or incorrect entries, can distort AI models. For example, in a retail dataset, duplicate customer records with slight variations in name (e.g., "John Doe" and "J. Doe") can lead to inflated sales metrics. Address this by using data deduplication tools or applying fuzzy matching techniques to identify and merge similar records.
Inconsistent Formats: Inconsistent data formats can impede model training. Consider a healthcare dataset where some patient ages are recorded as "30 years" and others as "30 yrs." Similarly, one file might use "Yes/No" for consent, while another uses "True/False." Using scripting languages like Python with libraries like Pandas can standardize these formats quickly.
Missing Data: Missing data points can skew analysis. For instance, if 30% of survey respondents skip the income question, AI models predicting spending behavior might produce unreliable results. Address this by using imputation techniques (e.g., filling gaps with mean or median values) or training models specifically designed to handle missing values, like XGBoost.
Closing thoughts
The success of AI projects starts with the quality of the data they rely on. I hope you remember the earlier explanation on “Garbage In, Garbage out”. If you feed Inconsistent, inaccurate, or incomplete data the outcome will lead to unreliable insights, delays, and missed opportunities.
The opportunity cost starts from delay in the POC’s to the production adoption with the applications. Organizations that prioritize clean, reliable data as a foundation position themselves to drive innovation, efficiency, and customer satisfaction. By proactively addressing data quality challenges and implementing effective cleaning strategies, businesses can unlock AI's full potential and deliver transformative results.
Clean data isn’t just important—it’s the cornerstone of successful AI.
Thanks for reading DataByteGo - The Data Blog! This post is public so feel free to share it.