Quantifications of data— How large the prediction looks like
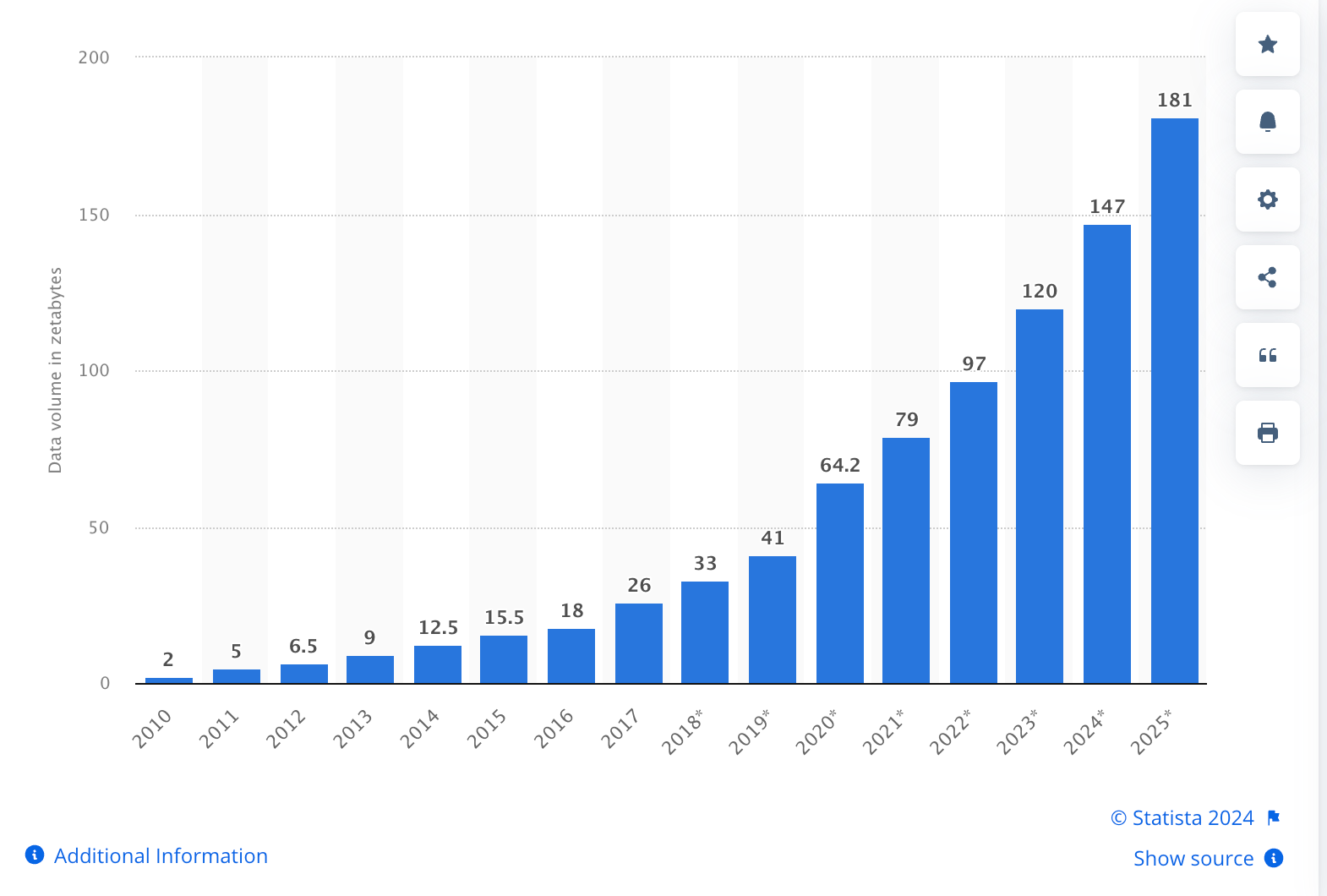
The International Data Corporation (IDC) estimates that by 2025 the sum of all data in the world will be in the order of 175 Zettabytes (one Zettabyte is 10^21 bytes). Most of that data will be unstructured, and only about 10% will be stored. Less will be analysed.
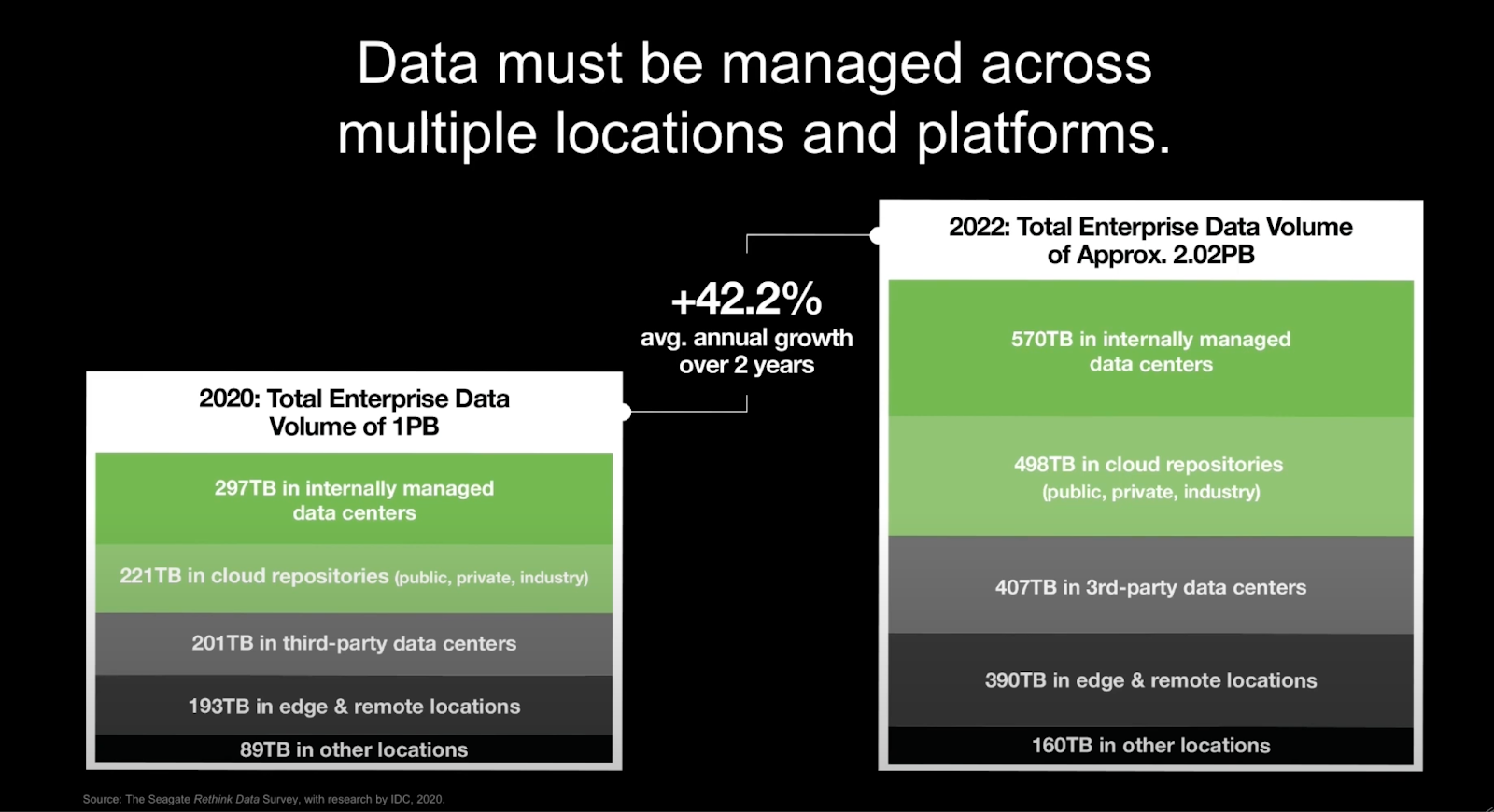
Seagate Technology forecasts that enterprise data will double from approximately 1 to 2 Petabytes (one Petabyte is 10^15 bytes) between 2020 and 2022. Approximately 30% of that data will be stored in internal data centres, 22% in cloud repositories, 20% in third party data centres, 19% will be at edge and remote locations, and the remaining 9% at other locations.
So data is big and growing. At current growth rates, it is estimated that the number of bits produced would exceed the number of atoms on Earth in about 350 years – a physics-based constraint described as an information catastrophe.
The rate of data growth is reflected in the rapid increase of storage centres. For example, the number of hyperscale centres is reported to have doubled between 2015 and 2020. Microsoft, Amazon and Google own over half of the 600 hyperscale centres around the world.
And in the age of Internet data moves around. Cisco estimates that global IP data traffic has grown 3-fold between 2016 and 2021, reaching 3.3 Zettabytes per year. Of that traffic, 46% is done via WiFi, 37% via wired connections, and 17% via mobile networks. Mobile and WiFi data transmissions have increased their share of total transmissions over the last five years, at the expense of wired transmissions.
Building Data Muscle for AI Innovation
As AI becomes ubiquitous, the models powering it require more high-quality data with increasing complexity.
The amount of global data being produced is accelerating, predicted to expand to 180 zettabytes by 2025, which is nearly double what it was in 2022. This explosion of data—both structured and unstructured—presents organizations with data management challenges that must be tackled head-on to unlock the power of AI.
To overcome these challenges, organizations need to build data products, processes, and platforms that ensure data is well-governed yet easily accessible and usable for those who need it. For Capital One, this has meant focusing on three core principles: standardization, automation, and centralization.
Establishing data standardization from the moment of creation involves defining clear rules and governance around metadata and data to maintain consistency and reliability in downstream data-powered experiences. We’re developing modular, reusable data management tools that can be integrated directly into our platforms and pipelines, ensuring standards are upheld at every stage.
However, even with strong standards, managing large volumes of data can strain existing processes. To adapt, it’s essential to both improve data quality and reduce manual workload for data producers, owners, and users. This requires identifying redundancies and automating labor-intensive, repetitive tasks—like data registration, metadata management, and ownership updates—allowing data users to focus on innovation.
What is Unstructured Data ETL?
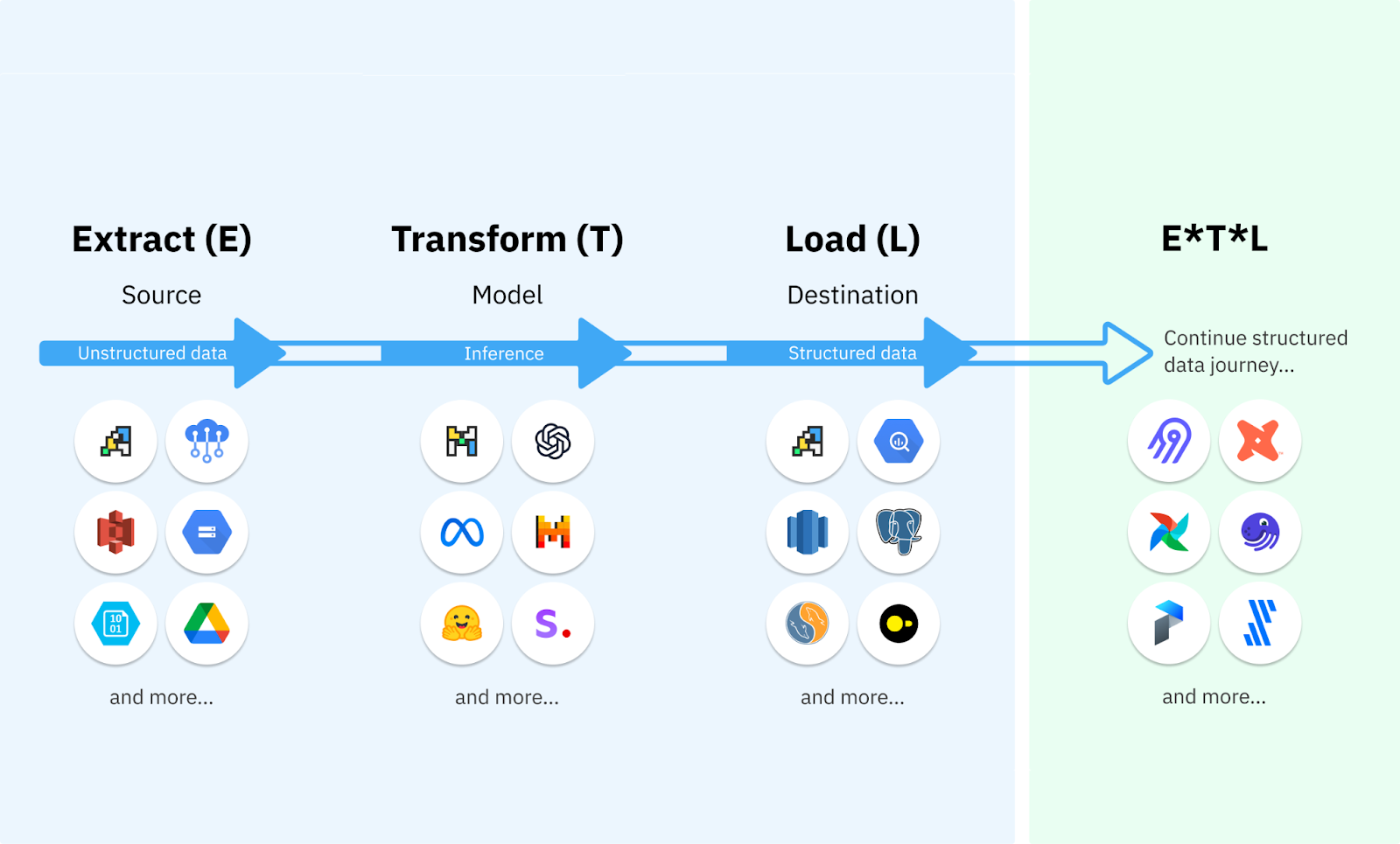
Unstructured data ETL is an innovative approach to automating the end-to-end processing of unstructured data at scale.
It combines the power of AI with traditional data engineering to extract, transform, and load data from diverse sources and formats.
The key components of unstructured data ETL are:
Data Sources: Unstructured data sources such as websites, PDFs, CSVs, emails, presentations.
Extract: Automatically extract the data from the sources
Transform: Automatically clean and format the data into structured formats
Load: Deliver transformed data into databases or via APIs for downstream applications
Data Consumers: Data warehouses, BI tools, or business applications
Traditionally, processing unstructured data has been a manual task that requires developers to use various tools, such as web scrapers and document processors, and to write custom code for extracting, transforming, and loading data from each individual source. This approach is time-consuming, labor-intensive, and prone to errors.
Large language models efficiently handle the complexity and variability of unstructured data sources, largely automating this process. When a website or PDF layout changes, rule-based systems often break. Using AI, we can adapt to these changes and make data pipelines more resilient and maintenance-free.
👟 A step back
Data extraction from unstructured file documents has been around for decades. Businesses have long relied on documents like purchase orders, receipts, legal contracts, and reports. However, these documents (in formats like PDF and Word) vary greatly in structure depending on the vendor, industry, or compliance standards, making consistent information extraction and logical structuring a challenge. Early solutions relied on basic parsing methods, which soon evolved to include OCR (Optical Character Recognition) to improve the extraction of information from these diverse document types. Many services address this need, starting with independent services such as Adobe PDF Services to parse their very own PDF files, as well as cloud providers like Amazon with Textract or Azure AI Document Intelligence. Many open-source libraries also offer different levels of parsing, from simple text extraction to OCR engines like Tesseract, one of the most popular open-source OCR engines. Nowadays, most OCR engines have evolved to use machine learning and deep learning. For example, Tesseract introduced the use of neural net since the release of Tesseract 4 in 2018. The implementation of machine learning and deep learning brought a leap forward for OCR engines, providing better accuracy in extracting data from documents and converting images to text.
What’s new then?
The real innovation today lies in transformer-based models, like Large Language Models (LLMs), which can understand context and process documents at a deeper level. While OCR engines are now adept at extracting raw text and content, GenAI enables us to take it further by summarizing, classifying, and even structuring data from these documents. However, challenges remain—LLMs grasp text well but often struggle with understanding its hierarchy. Hierarchical structures, such as titles, paragraphs, bold or italicized text, provide essential cues for humans, and similar hierarchies are found in websites via HTML. To improve document comprehension for LLMs, especially in RAG pipelines, new tools have emerged to bridge this gap by enhancing models' understanding of document structure.
Use Cases of Unstructured Data ETL
Automated ETL for unstructured data extends beyond traditional and basic AI applications to more complex, specialized use cases. Advanced ETL capabilities support sophisticated data analysis and AI model training, providing significant value for companies looking to optimize decision-making, enhance automation, and improve customer experiences.
Advanced Traditional Use Cases
Automated Financial Statement Processing:
Fraud Detection in Financial Records: ETL pipelines examine financial documents for irregularities or suspicious entries, assisting compliance teams in detecting fraud early.
Real-Time Financial Health Monitoring: Continuously extracts and analyzes key financial data (e.g., balance sheets, cash flow statements) for CFOs and financial analysts to provide a near-real-time view of the company’s financial health.
Contract and Legal Document Processing:
Automated Clause Extraction for Contract Review: ETL extracts and categorizes important clauses from contracts, enabling legal teams to quickly assess key terms, obligations, and renewal dates.
Risk Analysis in Regulatory Documents: Analyzes regulatory documents to highlight potential risks or compliance requirements, especially valuable for industries like finance and healthcare where regulations frequently change.
Customer Support Enhancement through Multi-Channel Analysis:
Automated Prioritization of Support Requests: ETL categorizes and prioritizes support tickets based on urgency, sentiment, and past interactions, helping customer service teams respond faster to critical issues.
Sentiment and Issue Trend Analysis Across Channels: Combines data from emails, chat logs, and support tickets to identify recurring issues and customer sentiments, allowing teams to proactively address common problems.
Intelligent Market Research:
Competitive Product Feature Analysis: Extracts data from competitor websites, press releases, and product specifications to build a comparative view of product features and market positioning.
Pricing Strategy Optimization: Integrates pricing data from multiple channels (e.g., competitors, e-commerce platforms) and tracks changes over time, enabling companies to adjust prices based on market dynamics.
Real Estate and Property Management:
Property Data Collection for Valuation Models: ETL gathers data from property listings, historical sales records, and tax documents, creating a structured dataset for real estate valuation models.
Tenant Feedback Analysis for Facility Improvements: Analyzes tenant feedback from emails, surveys, and maintenance requests to prioritize and address issues, helping property managers improve tenant satisfaction.
Automated Media Monitoring and Analysis:
News Aggregation and Sentiment Analysis: Collects data from news sources, blog posts, and opinion pieces to gauge sentiment and public opinion on specific topics, helping companies and PR teams manage brand image.
Competitor Media Coverage Analysis: Analyzes competitor mentions across media channels, identifying strengths, weaknesses, and strategies used by competitors in the public domain.
Product Development and Quality Control:
Customer Feedback Categorization: ETL extracts and categorizes feedback from various sources (e.g., product reviews, surveys) to help product teams prioritize features or improvements.
Defect Pattern Detection in Manufacturing Reports: Analyzes unstructured data from incident and quality control reports to identify recurring defects or bottlenecks in the manufacturing process.
AI data preparation use cases:
1. Advanced RAG Architectures for Enhanced Question-Answering Systems
Contextual Search Over Complex, Multi-Format Data:
RAG systems are enhanced to not only retrieve information but also understand context across formats like text, images, and tables within a single query. For example, a RAG system could pull information from text fields in a report, extract relevant figures from embedded charts, and answer questions with contextualized, multi-format insights. This capability is crucial for fields like finance, where context from tables, charts, and textual explanations must be synthesized for accurate answers.
Temporal Question-Answering with Real-Time Data Updates:
This involves real-time or near-real-time integration of newly ingested data, enabling RAG systems to answer questions with the most current information available. Ideal for fields like news or social media analysis, where up-to-the-minute information is critical, this setup allows AI to respond to questions with a "time-awareness" feature, offering context-specific insights based on recent events or data changes.
Domain-Specific RAG for Specialized Industries:
Advanced RAG configurations are tailored for specific domains, such as legal, medical, or regulatory fields, where the AI is trained on and retrieves from only the most relevant, industry-specific data. In healthcare, for example, RAG-powered question-answering might retrieve data from complex medical records, journal articles, and clinical studies, aiding healthcare professionals in accessing critical insights across a variety of medical data formats.
2. High-Precision Data Extraction from Diverse PDFs
Multi-Layered PDF Extraction with Contextual Understanding:
Advanced ETL for PDFs incorporates layers of context, understanding document structures (e.g., tables, footnotes, and headers) and relational cues between sections, rather than treating content as standalone text. For instance, in financial reports, the system can recognize and link figures in income statements to contextual explanations, providing a more cohesive and accurate extraction.
Smart Annotation and Tagging for PDF Data Organization:
Automatically annotates and tags extracted content based on its significance, type, or topic, which can be critical for organizing and categorizing data in industries like legal or finance. In legal applications, for instance, ETL can tag document clauses by type (e.g., confidentiality, liability) or importance, helping legal teams quickly access relevant clauses without manual search.
Extraction from Scanned and Low-Quality PDFs with OCR Enhancement:
Combines OCR with AI-driven error correction to extract text from low-quality or scanned documents. This use case is beneficial in industries like government or insurance, where many records are still paper-based. Enhanced OCR improves accuracy in extracting data from old documents, making it possible to digitize and leverage legacy records for AI training or analytics.
3. Automated Collection and Preparation of Web Data for Specialized LLM Usage
Continuous and Adaptive Web Data Curation for Real-Time Model Training:
Establishes continuous pipelines that curate, filter, and prepare relevant web data in real-time, allowing LLMs to stay updated with the latest industry knowledge and trends. For example, an LLM trained for financial analysis could automatically collect market news, earnings reports, and regulatory changes, enabling it to provide the latest insights without manual data input.
Content Filtering and Relevancy Scoring for Data Quality Improvement:
Employs advanced filtering to ensure only high-quality, relevant content is included in the training dataset. This involves scoring content based on factors such as credibility, timeliness, and relevance to specific topics, reducing noise and enhancing the quality of LLM responses. For instance, in the field of science, only data from reputable sources (e.g., peer-reviewed journals) would be included, making the LLM better suited for accurate scientific discourse.
Data Augmentation and Synthetic Data Generation from Web Data:
Automatically generates synthetic data or enriches existing data based on patterns in collected web data, which can enhance LLM performance without manual data labeling. In customer service AI, for example, synthetic data might be generated to handle rare query types by training the model on a wider variety of potential customer inquiries, thus preparing it for nuanced or complex questions.
Language-Specific and Regional Web Data Curation for Multilingual Models:
Aggregates web data in various languages and regions, supporting multilingual LLM models that understand cultural nuances and regional terminology. For instance, an LLM for e-commerce could be trained on user reviews and product descriptions from different regions, allowing it to handle localized queries or offer culturally relevant recommendations.
The AI data preparation market is expected to experience significant growth in the coming years, and unstructured data ETL will play a crucial role.
Conclusion
Unstructured data ETL is the missing piece in the modern data stack. Data pipelines that took weeks to build, test, and deploy, can now be automated end-to-end in a fraction of the time with the use of tools like unstructured.io or Kadoa. For the first time, we have turnkey solutions for handling unstructured data in any format and from any source.
Enterprises that apply this new paradigm will be able to fully leverage their data assets (e.g. for LLMs), make better decisions faster, and operate more efficiently.
Data ist (still) the new oil, but now we have the tools to refine it efficiently.




![[AI/LLM Series] Building a Smarter Data Pipeline for LLM & RAG: The Key to Enhanced Accuracy and Performance](https://substackcdn.com/image/fetch/$s_!jaF_!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F31f96679-3b4c-4cc3-95e7-f2c29c6c2111_1219x588.jpeg)

