
[AI/LLM Series] Building a smarter data pipeline for LLM & RAG: The key to enhanced accuracy and performance[part-2]
Want to get the most out of your LLM and RAG systems? It all starts with a solid data pipeline. In this guide, we’ll break down how simple techniques like chunking and cleaning your data can boost acc

In the part1- of this blog , we have covered
Breaking data into chunks helps RAG systems work better. By splitting large datasets into smaller, manageable pieces, RAG systems can process information more accurately and provide relevant responses for search.
Clean data is key to getting good results. RAG systems rely on clean, well-organized data to deliver reliable answers. Messy or inconsistent data can lead to mistakes or irrelevant information.
In this post we are going to cover:
Poorly chunked or unclean data hurts performance. If data isn’t properly chunked or cleaned, RAG systems might return incomplete, confusing, or inaccurate results, which can frustrate users.
A well-structured data pipeline makes all the difference. Having a smooth process for organizing and cleaning data ensures RAG systems run efficiently, leading to better insights and overall user experience.
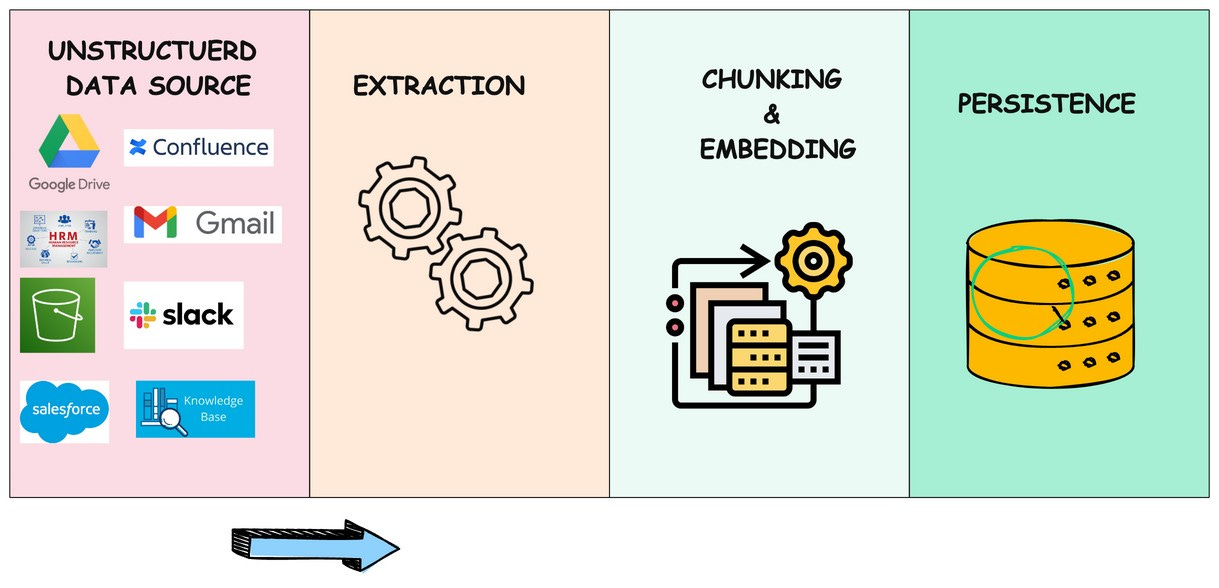
Why It Matters
In short, data chunking and data cleaning are vital for making sure RAG systems work well. Chunking helps manage and understand information better, while cleaning ensures that the data is accurate and useful. Without these steps, the system might struggle with messy or incorrect information, leading to less effective and reliable results.
Data Chunking
Text Chunking
Contextual Chunking
Hierarchical Chunking
Content-Based Chunking
Task-Specific Chunking
Data cleaning or "Text Normalization" or "Text Preprocessing."
Text Chunking
Sentence Chunking: Divides text into individual sentences. Useful for tasks that require fine-grained context, such as summarization or answering specific questions within a single sentence.
Paragraph Chunking: Splits text into paragraphs. This is suitable for maintaining larger context within a document, which is useful for generating coherent responses based on paragraph-level information.
Document Chunking: Breaks down entire documents into manageable chunks, such as sections or chapters. This approach helps in handling lengthy documents and retrieving relevant sections when processing queries.
Contextual Chunking
Fixed-Size Chunking: Divides text into chunks of a predefined size, such as a certain number of tokens or characters. This approach ensures uniformity in chunk size but may sometimes cut off context.
Dynamic Chunking: Adjusts chunk size based on the content or context, ensuring that chunks are neither too small nor too large. This method helps in maintaining meaningful context and improving the quality of responses.
Overlapping Chunking: Creates chunks with overlapping content to capture context that spans across chunk boundaries. This is particularly useful for tasks where understanding context across multiple chunks is essential, such as in continuous text generation.
Hierarchical Chunking
Hierarchical Document Chunking: Organizes data into a hierarchical structure, such as dividing a document into chapters, sections, and subsections. This allows the RAG system to retrieve information at different levels of granularity, enhancing context retrieval.
Multi-Level Chunking: Combines various chunking strategies at different levels. For example, a document might be chunked into paragraphs first and then further divided into sentences. This multi-level approach helps in fine-tuning the retrieval process and generating more accurate responses.
Content-Based Chunking
Semantic Chunking: Uses natural language processing (NLP) techniques to chunk text based on semantic units, such as topics or themes. This approach focuses on dividing text into chunks that are contextually meaningful, improving the relevance of retrieved information.
Entity-Based Chunking: Segments text based on specific entities, such as people, organizations, or locations. This method is useful for tasks that require detailed information about particular entities and helps in retrieving relevant chunks related to those entities.
Task-Specific Chunking
Query-Based Chunking: Dynamically creates chunks based on the specific queries or tasks at hand. For example, when a user asks a question about a particular topic, the system generates chunks that are most relevant to that topic.
Feature-Based Chunking: Focuses on dividing text based on specific features or attributes required for a task, such as extracting key phrases or keywords. This method helps in retrieving and processing information that aligns with the desired features.
The process of cleaning data to remove ASCII characters, bullet points, special characters, and other formatting issues is commonly referred to as "Text Normalization" or "Text Preprocessing."
Here’s a breakdown of these terms and their relevance:
Text Normalization
Text normalization involves converting text into a consistent format by removing or standardizing certain elements. This includes stripping out unwanted characters, correcting inconsistencies, and preparing the text for further analysis or processing.
Examples:
ASCII Removal: Removing non-printable ASCII characters that might have been included during data collection or encoding.
Bullet Point Removal: Eliminating bullet points from lists to ensure that the text is uniformly formatted.
Special Characters Removal: Removing or replacing special characters such as emojis, symbols, or non-standard punctuation that may not be relevant to the analysis.
Text Preprocessing
Text preprocessing encompasses a range of techniques used to clean and prepare text data for natural language processing (NLP) or machine learning tasks. This includes text normalization as well as other preprocessing steps like tokenization, stemming, and lemmatization.
Examples:
Special Characters Removal: Cleaning up text by removing characters that are not part of standard language, such as @, #, $, or other symbols that could interfere with text analysis.
Whitespace Handling: Removing unnecessary whitespace or extra spaces that may have been inadvertently included.
Text Normalization
Lowercasing
Converts all characters in the text to lowercase to ensure consistency by removing case sensitivity, which is crucial for tasks like text comparison and searching.
Example: Converting “Hello World” to “hello world.”Removing Special Characters
Eliminates characters that are not letters or numbers, such as punctuation marks, symbols, or emojis. This cleans the text for better analysis and prevents the inclusion of irrelevant data.
Example: Removing “Hello! How are you? 😊” to “Hello How are you.”Removing Numbers
Deletes numeric values from the text to focus on the textual content, especially when numbers are irrelevant to the analysis.
Example: Transforming “The price is 100 dollars” to “The price is dollars.”Removing Extra Whitespace
Removes extra spaces, tabs, or newline characters to ensure a clean and consistent format for text data.
Example: Converting “Hello World” to “Hello World.”Normalizing Accented Characters
Converts accented characters to their base form, standardizing text for better matching and searching.
Example: Converting “café” to “cafe.”Expanding Contractions
Replaces contractions with their expanded forms, making the text more uniform for natural language processing.
Example: Converting “don’t” to “do not.”Removing HTML Tags
Strips HTML tags from the text to clean it, especially when extracted from web pages.
Example: Transforming “<p>Hello World</p>” to “Hello World.”Unicode Normalization
Converts text to a standard Unicode format, ensuring consistent representation of characters, useful for multilingual text.
Example: Normalizing “café” to its canonical Unicode representation.
Text Preprocessing
Tokenization
Splits text into individual units, such as words or sentences, for further analysis.
Example: Tokenizing “Hello World” into ["Hello", "World"].Lemmatization
Reduces words to their base or dictionary form, grouping inflected forms of a word to aid in text analysis.
Example: Converting “running” and “ran” to “run.”Stemming
Trims words to their root form by removing suffixes, though it may not always produce meaningful results.
Example: Converting “running” and “runner” to “run.”Stop Words Removal
Removes common words that are usually not meaningful in text analysis (e.g., “and”, “the”, “is”).
Example: Removing “The cat is on the mat” to “cat mat.”Part-of-Speech Tagging
Assigns parts of speech (e.g., noun, verb) to each word in the text, providing grammatical context for advanced analysis.
Example: Tagging “She runs fast” as [("She", "PRP"), ("runs", "VBZ"), ("fast", "RB")].Named Entity Recognition (NER)
Identifies and classifies entities in the text, such as people, organizations, and locations, to extract meaningful information.
Example: Recognizing “Barack Obama” as a person and “New York” as a location.Text Vectorization
Converts text into numerical vectors for machine learning models, using techniques like Bag-of-Words, TF-IDF, Word2Vec, or BERT embeddings.
Example: Converting “Hello World” into a vector representation.Removing Non-Text Elements
Eliminates elements like URLs, email addresses, or phone numbers, focusing the analysis on the actual content.
Example: Removing “Visit us at http://example.com” to “Visit us at.”Spelling Correction
Identifies and corrects spelling errors, improving the quality of the text data by fixing typographical mistakes.
Example: Correcting “teh” to “the.”Text Decomposition
Breaks down complex texts into simpler or more granular components, simplifying analysis by working with smaller, manageable segments.
Example: Breaking down “The quick brown fox jumps over the lazy dog” into key phrases or segments.
In Summary, Data chunking and data cleaning are the Key components of building a good RAG data pipeline. Both components contribute to the data quality and accuracy for the model training as as well for Data retrieval accuracy.
Properly applied data chunking can reduce training time by up to 30%, while also improving accuracy
By eliminating irrelevant or misleading data points, cleaning ensures that the model isn’t compromised by noise or outdated information, leading to more accurate predictions. Thorough data cleaning can improve model accuracy by as much as 25%
References:
Four Data Cleaning Techniques to Improve Large Language Model (LLM) Performance: https://medium.com/intel-tech/four-data-cleaning-techniques-to-improve-large-language-model-llm-performance-77bee9003625
Youtube: Why Do You Still Need Clean Data With Retrieval Augmented …
Retrieval-augmented Generation (RAG) Explained: Understanding Key Concepts: https://www.datastax.com/guides/what-is-retrieval-augmented-generation
Some other related and interesting topics:
AI/ML- Brief Introduction to Retrieval Augmented Generation- RAG
https://www.databytego.com/p/aiml-brief-introduction-to-retrieval
Navigating 4 stages of Cloud Privacy for AI and ML Strategies:
https://www.databytego.com/p/navigating-4-stages-of-cloud-privacy
The Rise of Modern Databases with AI/ML:
The Rise of Modern Databases with AI/ML
·
With the rise of the Modern tech stack and AI/ML, unstructured data generation and usage has been significantly increased. This journey has led to a huge database transformation, which doesn’t stop with simple row and column stores.
