
Metadata-Driven Data Platforms: The Missing Piece in Modern Data Stacks (Part-1)
Why Your Data Stack or AI data platform Isn’t Complete Without Metadata-Driven Automation and Trust


1-Minute TL;DR
Modern data stacks are powerful but flimsy without metadata. Metadata is the unseen force that connects, governs, and automates every part of the system. Active metadata enables automated lineage, access control, orchestration, and observability. This blog explores how metadata-driven platforms can solve real-world problems like broken dashboards, security gaps, and Machine learning model drift. If you're scaling a data platform and not prioritizing metadata, you're flying blind.

Here is a interesting story which you call can relate to..
It was launch day. Months of work had gone into building dashboards, fine-tuning metrics, and prepping the data flows. Snowflake was set up, dbt models were deployed, and Airflow pipelines were humming.
Then, right before the go-live… boom. A critical dashboard broke. Revenue numbers disappeared. And nobody knew why.
The team scrambled. SQL queries, pipeline logs, Slack threads. Hours passed.
The root cause? A column upstream had been removed. No alerts. No data lineage. No warning.
That’s when it became clear: the issue wasn’t the tools, it was the missing link between them.
That missing link was metadata.
Not just documentation, but active metadata which is real-time, queryable, and automated. The kind that could’ve spotted the change, flagged it, or even kicked off a fix before anyone noticed.
Why Metadata Is the Brain of Your Data Stack
Metadata is often dismissed as just “data about data.” But in modern data stacks, it’s the connective tissue, the interpreter, and the control center.
“If data is the new oil, metadata is the refinery.” — DataHub team
Think of it this way:
Without metadata, your dashboards are disconnected.
Your transformations are brittle.
Your lineage is tribal knowledge.
Your governance? Manual. Error-prone. Risky.
“Treat metadata as the platform, not just a side feature.”
Here are some intrustry prediction and forecasting(Sources are mentioned under reference section)
By 2026, Gartner predicts that 30% of organizations will adopt active metadata practices to accelerate automation, insights, and recommendations.
Only 15% of companies rate their data culture maturity as top-tier, indicating widespread opportunity—plus, 87% of data leaders say catalogs are essential to build strong data culture.
Organizations using lineage metadata see up to 47% faster data engineering velocity.
Over 50% of ML models in production suffer degraded performance from poor data quality or undocumented lineage—metadata is critical to trustworthiness
Monte Carlo reports that active metadata reduces time to root cause by ~30–80% depending on pipeline complexity.
From Invisible to Indispensable: Active Metadata in Action
Every modern enterprise from small scale to large B2B enterprises are already data-driven or in started the journey. To keep up, organizations are building sophisticated data stacks powered by best-in-class tools for the entire data pipeline for exmaple: warehouses like Snowflake, BigQuery, and Databricks; transformation frameworks like dbt; streaming engines such as Kafka and Redpanda; and orchestrators like Airflow, Dagster, or Prefect.
Data ingestion is handled through tools like Fivetran, Airbyte, and Stitch, while dashboards come to life in Looker, Tableau, or Power BI. Machine learning pipelines run quietly powering real-time personalization and predictions.
From raw data to business insights, the modern data stack has become modular, cloud-native, and incredibly powerful. But in the middle of this innovation and tech euphoria of AI and data driven adoption there a blind spot: metadata.
Here is an simple example which shows the metadata gap and how enterprise can solve those.
⚠️ Problem: A new table was added to your lakehouse but wasn’t cataloged or tagged. Now, data privacy risks are lurking.
✅ Solution: Active metadata auto-registers datasets, applies PII tags, and triggers validation flows before anyone sees it in production.
Metadata is not just "data about data".
It's the operational glue, the silent observer, and the foundation of trust that holds your data stack together. It’s the entity that tells you:
Where did this dataset come from?
Who owns it?
How often is it refreshed?
What breaks if we drop a column?
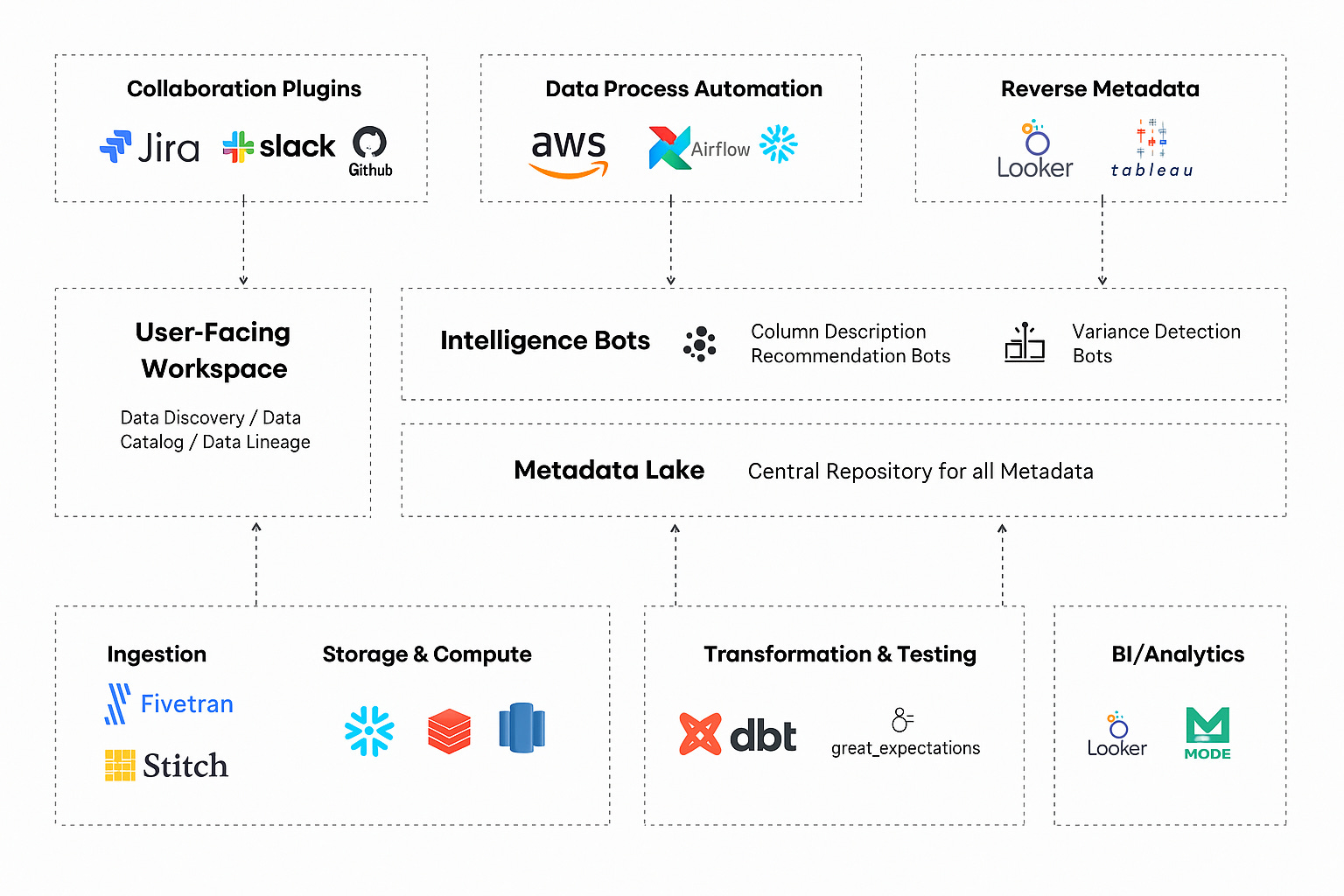
Source link
And yet, despite its potential, metadata is too often siloed in documentation tools, confined to platform UIs, or lost in tribal knowledge. When used proactively, metadata can do so much more than track lineage or manage glossaries. It can become the control plane of your data platform, driving automation, governance, observability, and even dynamic orchestration.
Consider this: in an ideal world, a new table added to the data lake automatically triggers a transformation job, registers itself in the catalog, tags itself for privacy compliance, and sends an alert if freshness drops. None of this would be possible without metadata working behind the scenes.
In this blog, we go deep into how metadata-driven platforms are reshaping data engineering—from automated DAG generation and self-healing pipelines to real-time lineage and AI-powered debugging. Let’s uncover how metadata is quietly becoming the engine of intelligent data systems.
What is Metadata (Really)?
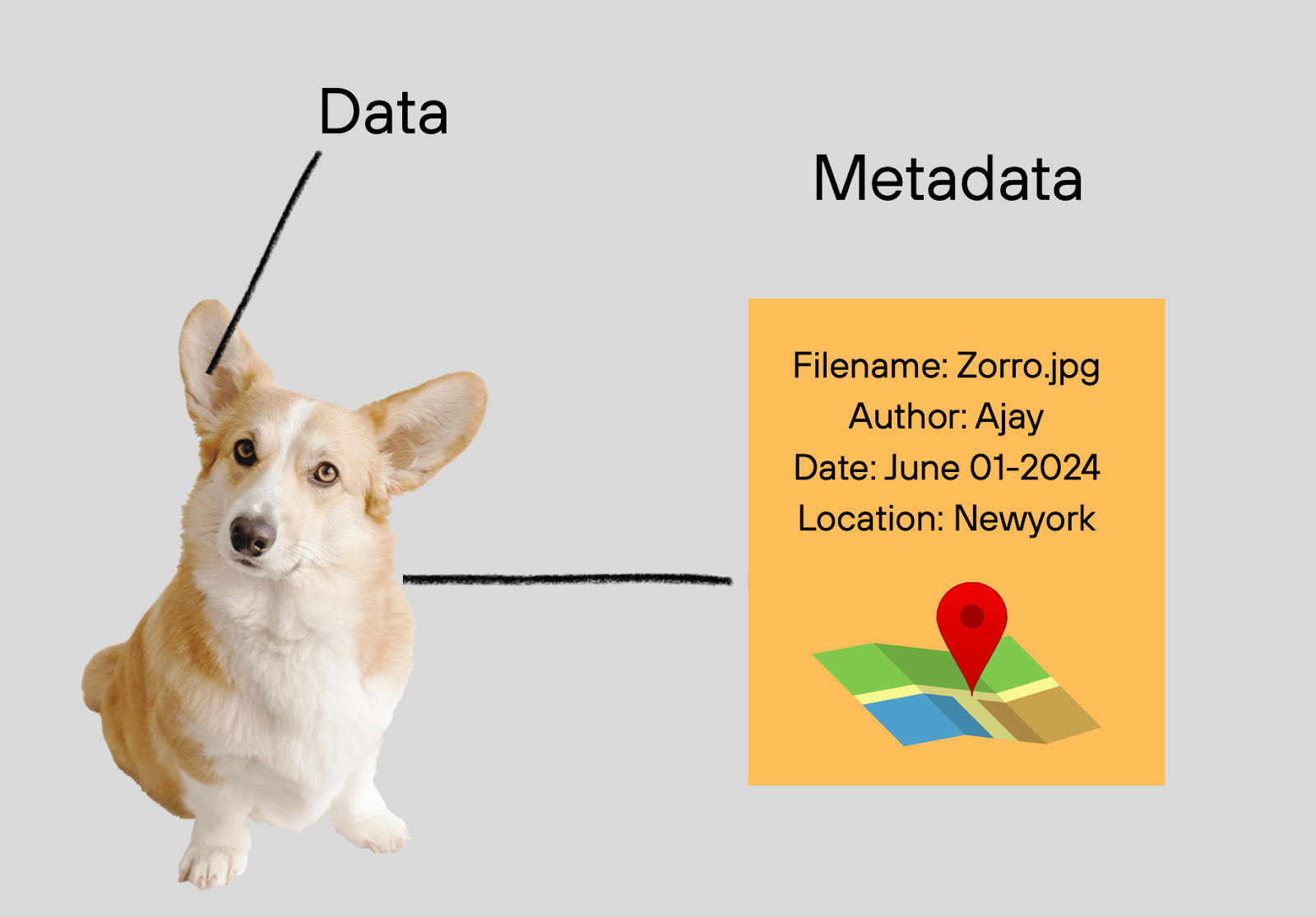
Metadata is one of the most simple yet very impactful elements of the data world. At its core:
Metadata = Data about data
But that's only the starting point.
In practice, metadata is the descriptive, operational, and contextual information that breathes intelligence into your data systems. It's how your systems, tools, and people understand what the data means, how it's structured, where it comes from, and what should be done with it.
Let's break this down into real-world categories:
Technical Metadata: Describes the structural properties of data, such as table and column names, data types, file formats, and storage paths.
Example: A table named orders with a column order_date of type timestamp, stored as a Parquet file in an S3 bucket.Operational Metadata: Captures runtime and processing metrics like job duration, pipeline status, and data freshness.
Example: An Airflow DAG shows that a data pipeline ran for 17 minutes, failed twice, and refreshed the data 2 hours ago.Business Metadata: Provides business context, including KPI definitions, glossary terms, and asset ownership.
Example: The customer_churn_rate metric is defined as “% of customers who cancel in a month” and owned by the retention analytics team.Behavioral Metadata: Tracks how data is being used across the organization, including access frequency and query patterns.
Example: A Looker dashboard is accessed daily by marketing and frequently queries the user_activity table.Security & Compliance Metadata: Flags sensitive information and governs who can access or modify data.
Example: A column ssn is tagged as PII, triggering automatic masking in BI tools and limiting access to finance and HR teams.Social Metadata: Captures collaborative and human-generated signals about how data is perceived, used, and discussed across the organization.
Example: A dataset is starred by 14 analysts, commented on by a data steward clarifying a metric, and upvoted in the data catalog for its reliability.
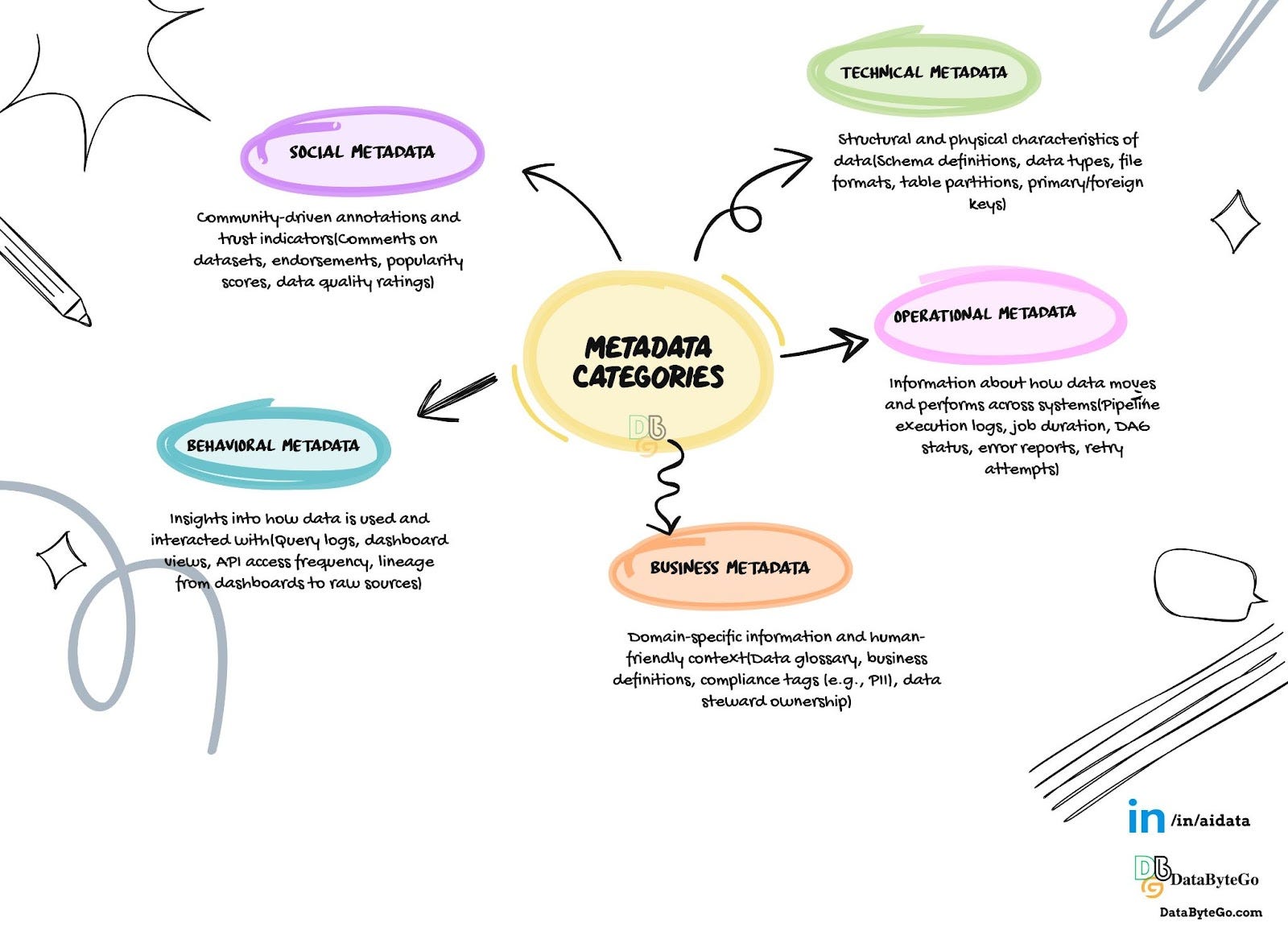
This layered metadata is essential not just for understanding your data but also for operating your platform at scale.
For example:
A table tagged as pii=true should be routed through a data masking step.
If pipeline logs reveal a 30% increase in runtime, your orchestrator can auto-trigger a health check.
Behavioral metadata can highlight which tables are mission-critical based on downstream dashboard usage.
“If data is the new oil, metadata is the refinery.” — DataHub team
Metadata transforms raw data into something useful, trustworthy, and actionable.
And the best part? Modern platforms are making this metadata live, queryable, and event-driven that means that your metadata doesn’t just describe your data; it drives how your platform behaves.
Real-World Problems Where Data Catalogs Are Critical
In theory and concepts, all the modern data stacks in the companies are seamless. But in real world enterprises has complex implementation and when the ecosystem of data lifecycle contains of dozens - If not hundreds of tools, datasets and transformation. In the middle of the complex system and processes data catalog serve as a critical and key layer that brings oder, traceability , scale and automation to the entire ecosystem. If powered by active metadata, catalog can help solve a lot of platform problems specially in the areas of Securuty, observability and AI readiness.
One of the most crtical domains where catalogs prove invaluable is data security and access management. Without a catalog, sensitive fields like Social Security Numbers (SSNs), financial records, or protected health information may be accessed by unauthorized users, either unknowingly or due to inconsistent enforcement of access policies across different tools. A metadata catalog helps solve this by enabling organizations to tag data assets with sensitivity labels such as pii, hipaa, or confidential.
🚨 1. Use case: Unauthorized Data Access
⚠️ Problem: An analyst unknowingly accesses raw PHI from a data lake.
✅ Solution: Catalogs like Collibra or Alation apply real-time access control policies (e.g., PII=true → mask data). Capital One classifies all datasets by sensitivity through a centralized metadata layer.
These tags can automatically trigger downstream actions like masking or encryption. Furthermore, access control can be programmatically enforced through role-based (RBAC) or attribute-based (ABAC) policies. Security teams can also generate real-time audits showing who accessed what data, when, and for what purpose. For example, Capital One uses a centralized metadata layer to classify data by sensitivity level and enforce access controls at scale. (source)
Another area where catalogs make a significant impact is observability and root cause analysis. When a dashboard suddenly breaks or a metric value looks suspicious, the hardest part isn’t fixing the issue—it’s diagnosing it. A good metadata catalog provides end-to-end data lineage that allows teams to trace a field all the way from a business dashboard back through transformation models, tables, and to the raw source. This lineage acts as a diagnostic map, dramatically reducing mean time to resolution (MTTR). Catalogs also integrate with data observability tools to provide alerts for stale datasets, schema drift, or job failures, while surfacing trust indicators such as freshness, frequency of access, and validation status. Airbnb, for example, reported reducing issue triage time by over 70% after implementing metadata-driven root cause tooling.
🚨 2. Use case: Broken Dashboards and Slow RCA
⚠️ Problem: A marketing dashboard suddenly drops to zero.
✅ Solution: Metadata catalogs with end-to-end lineage enable teams to backtrack across dbt, Airflow, and ingestion pipelines—reducing MTTR by 70%, as seen at Airbnb.
Finally, metadata catalogs are emerging as a cornerstone for AI and ML readiness. With enterprises racing to operationalize AI, one key bottleneck is preparing high-quality, well-documented, and compliant data pipelines. A data catalog helps by tagging datasets as structured or unstructured, annotating features with context and ownership, and tracking quality signals. This ensures that training data is not only valid but also explainable and ethically sourced. For instance, Google’s Vertex AI integrates tightly with their metadata catalog to allow ML engineers to curate training datasets with confidence and traceability.
🚨 3. Use case: AI/ML Model Degradation
⚠️ Problem: A model drifts silently due to undocumented changes in training data.
✅ Solution: Platforms like Google Vertex AI link feature metadata, freshness stats, and ownership—all visible in the metadata catalog for fast diagnosis and retraining.
Why This Matters Now
💡 Stat: 87% of data leaders say catalogs are essential for a strong data culture, yet only 15% of companies rate their data maturity as high.
That’s a massive gap—and a massive opportunity. Metadata is how we close it.
Modern metadata isn’t just a map—it’s the engine of intelligent data systems.
In Part 2, we’ll dive deep into how metadata transforms each layer of the data stack:
How ingestion pipelines use metadata for schema drift detection
How orchestration tools auto-generate DAGs using metadata tags
How BI tools surface trust indicators directly in dashboards
How governance becomes scalable, automated, and real-time
"Metadata empowers your stack to be context-aware and adaptive. It transforms passive pipelines into intelligent, self-regulating systems."
Stay tuned for real-world case studies from enterprises and a visual walkthrough of metadata-powered orchestration in action.
Previous articles :

![[AI/LLM Series] Building a smarter data pipeline for LLM & RAG: The key to enhanced accuracy and performance[part-2]](https://substackcdn.com/image/fetch/$s_!jaF_!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F31f96679-3b4c-4cc3-95e7-f2c29c6c2111_1219x588.jpeg)
