
Vector database and why it's Popular in AI
Understand Vector database in simple english and learn why AI based application are using vector database

There is a lot of buzz in the database market about vector databases, especially for AI/ML applications. Why have vector databases become so popular in the last 2 years, and how are they different from relational databases when it comes to AI/ML applications?
Let’s unlock this mystery today
In this blog, we will cover
What’s vector database - definition(both technical and also plain simple English)
Real-world application of vector database.
Understanding Vectors and how vector databases work.
How vector databases work with AI applications.
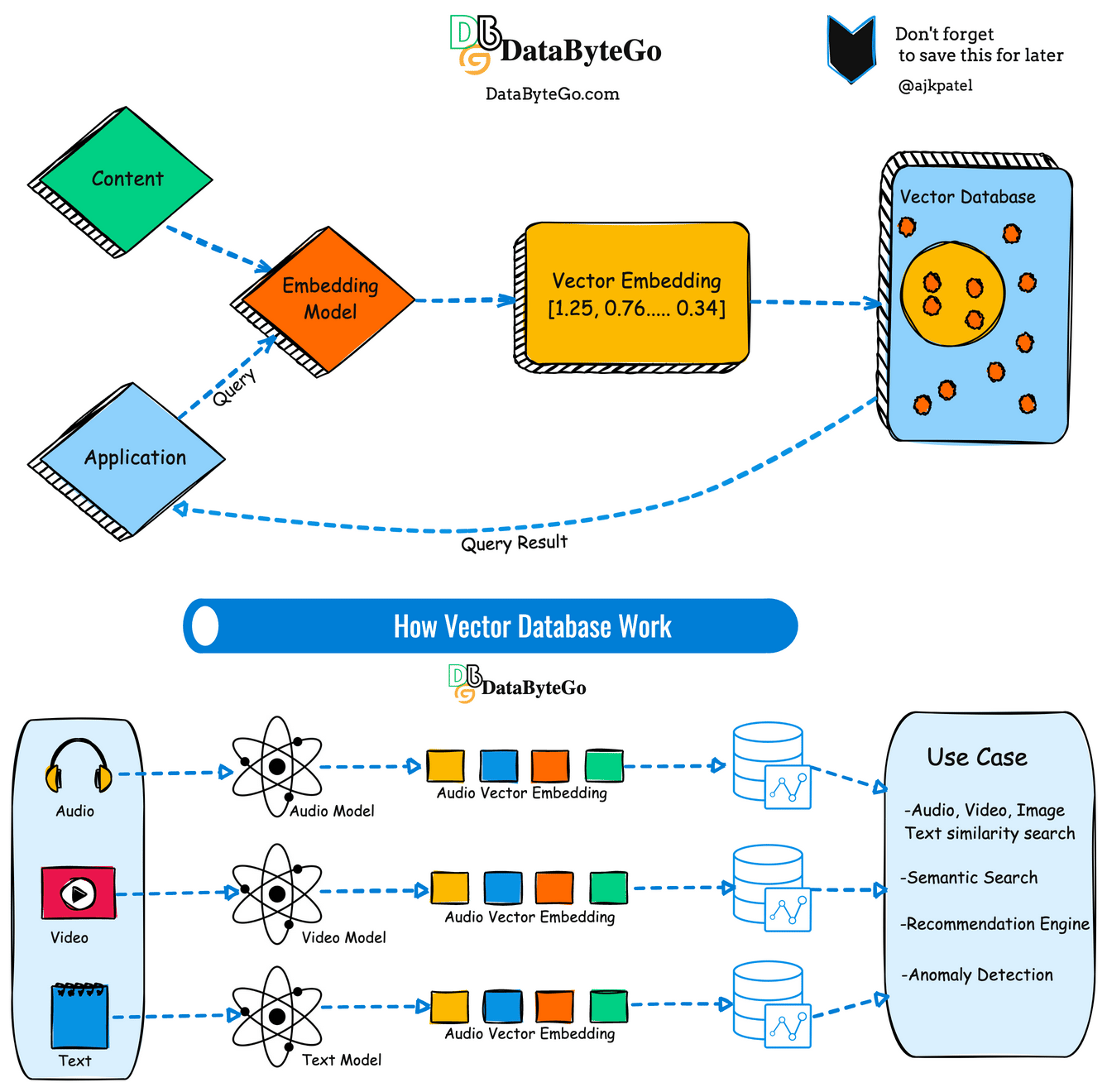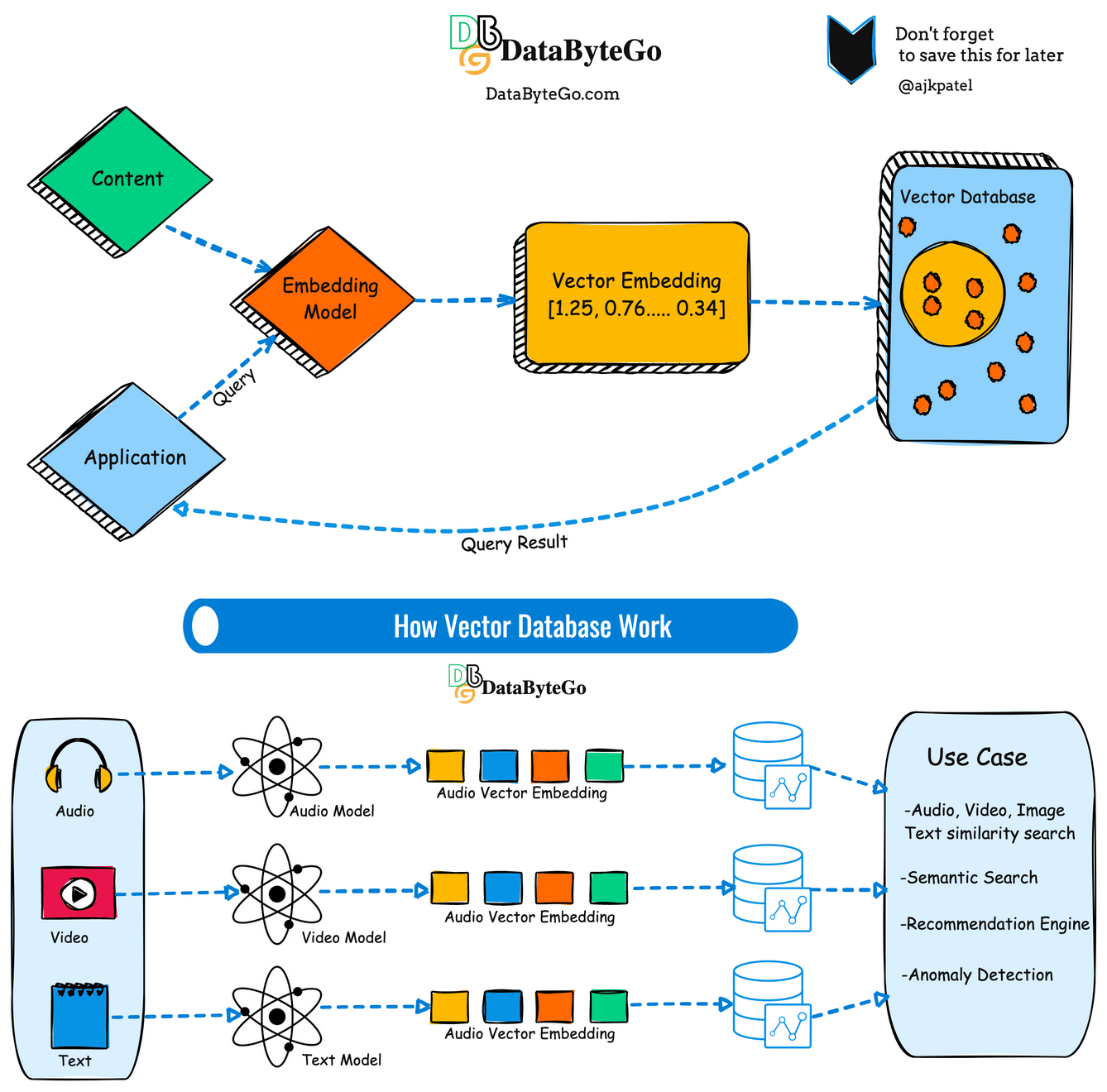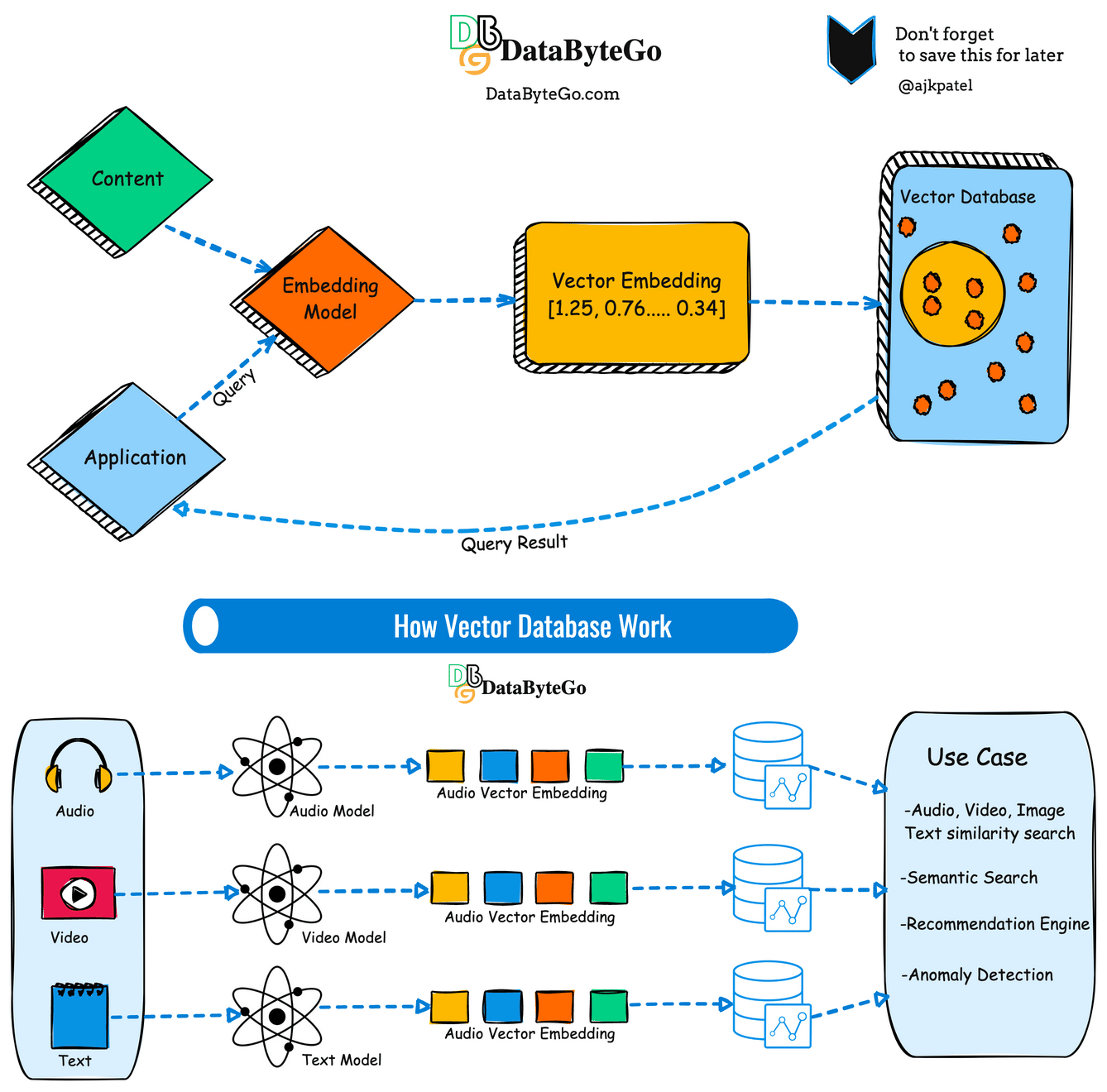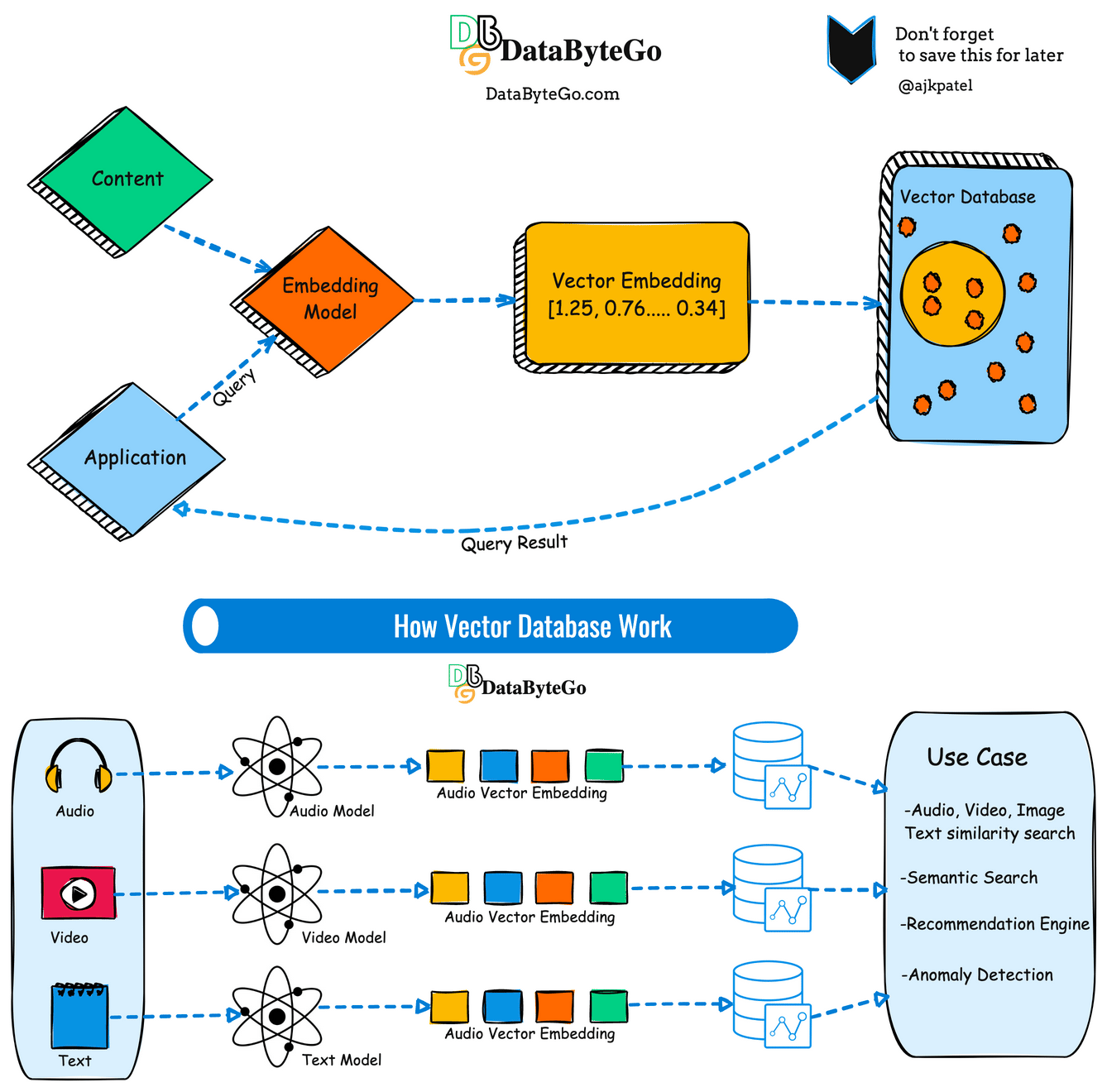
What’s a vector database?
A vector database is a specialized type of database designed to store efficiently and process vector data structures. In simple terms, vectors are mathematical representations of data points in multi-dimensional space, often used in various AI and machine learning applications.
Unlike traditional relational databases that store data in tables with rows and columns, vector databases organize data points as vectors, which consist of numerical values representing features or attributes of the data. These vectors can represent a wide range of information, including text, images, audio, and sensor data.
Applications in the Business World(includes AI)
Skip this part if you like to learn directly about vector databases.
Personalization and Recommendation Systems:
E-commerce: Recommending products to users based on their browsing history, purchase behavior, and similarities with other users.
Streaming Services: Suggesting movies, TV shows, or music based on user preferences, viewing history, and similarities with other users.
Content Platforms: Recommending articles, news stories, or social media posts based on user interests, engagement history, and content similarities.
Search and Information Retrieval:
Search Engines: Retrieving relevant documents, web pages, or multimedia content based on similarity to the user's query or browsing history.
Digital Asset Management: Finding images, videos, or audio files similar to a given asset for content reuse, archival, or creative inspiration.
Enterprise Search: Enabling employees to quickly find relevant documents, presentations, or knowledge base articles based on their content and similarities with past queries.
Customer Segmentation and Targeting:
Marketing Automation: Segmenting customers based on similarities in demographics, behavior, or preferences to deliver personalized marketing campaigns and promotions.
Customer Relationship Management (CRM): Grouping customers into segments for targeted communication, cross-selling, and upselling based on similarities in purchase history and interactions.
Ad Targeting: Identifying target audiences for advertising campaigns by analyzing similarities between existing customers and potential prospects based on their online behavior and characteristics.
Anomaly Detection and Pattern Recognition:
Cybersecurity: Detecting abnormal network traffic, unauthorized access attempts, or security breaches by comparing patterns with historical data and known attack signatures.
Fraud Detection: Identifying fraudulent transactions, account activities, or insurance claims by detecting deviations from normal behavior and similarities with known fraud patterns.
Quality Control and Manufacturing: Detecting defects, deviations, or anomalies in production processes by comparing sensor data, product characteristics, or quality metrics with historical norms and specifications.
Embedding and vector
Before we learn how vector database works, we need to learn about embeddings and vectors.
Let’s figure out how you can represent the word apple in numeric format or presentation
For properties related to the company “Apple”, we can think about company locations, whether the company trades or has stock, revenue, etc.
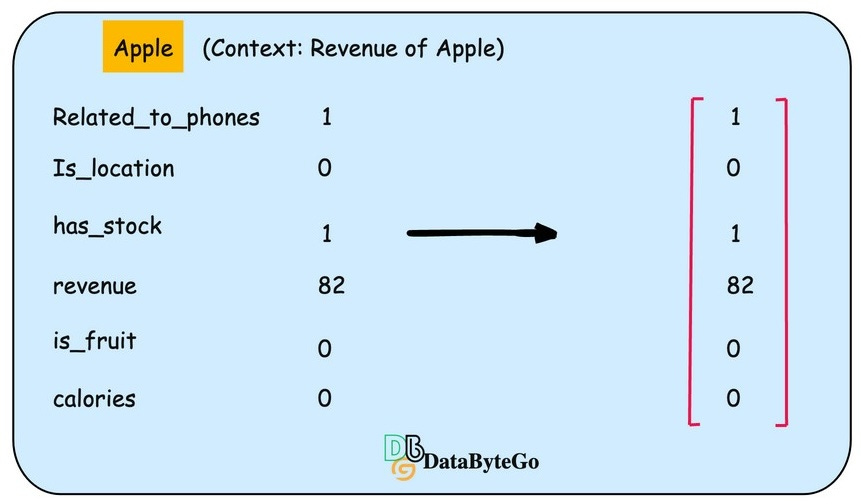
Now let's change the context and talk about the Apple as a fruit. Then, the properties will be changed according to the fruit, and the embedding will look something different because the values of the properties are a bit different.

Now let's take another example of fruit "Orange". If you see the second and the third vector are similar.
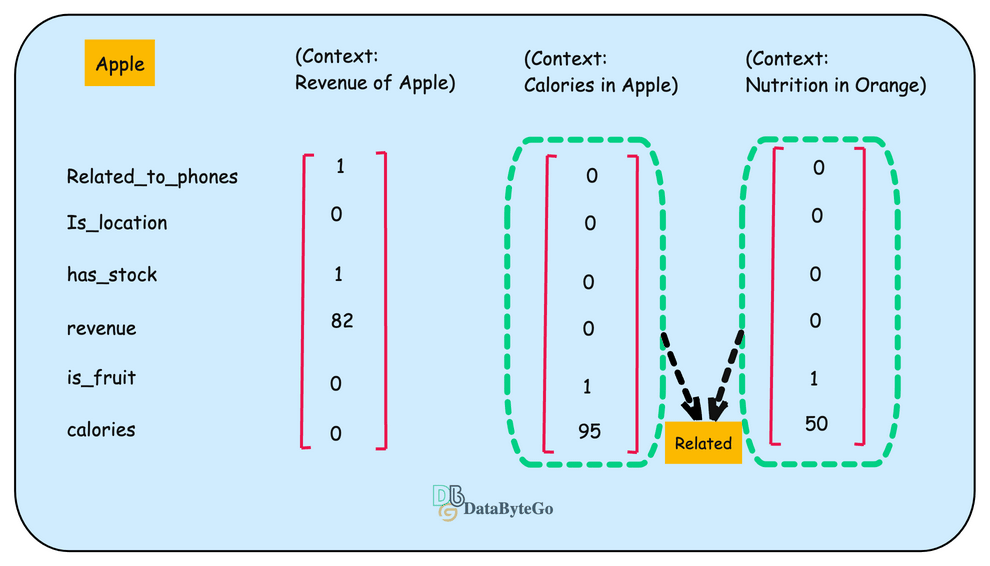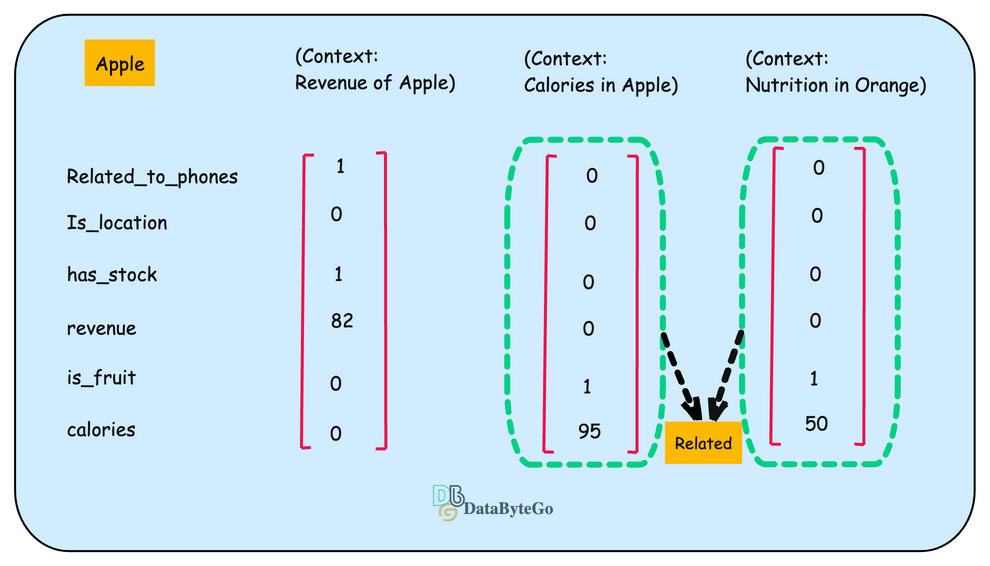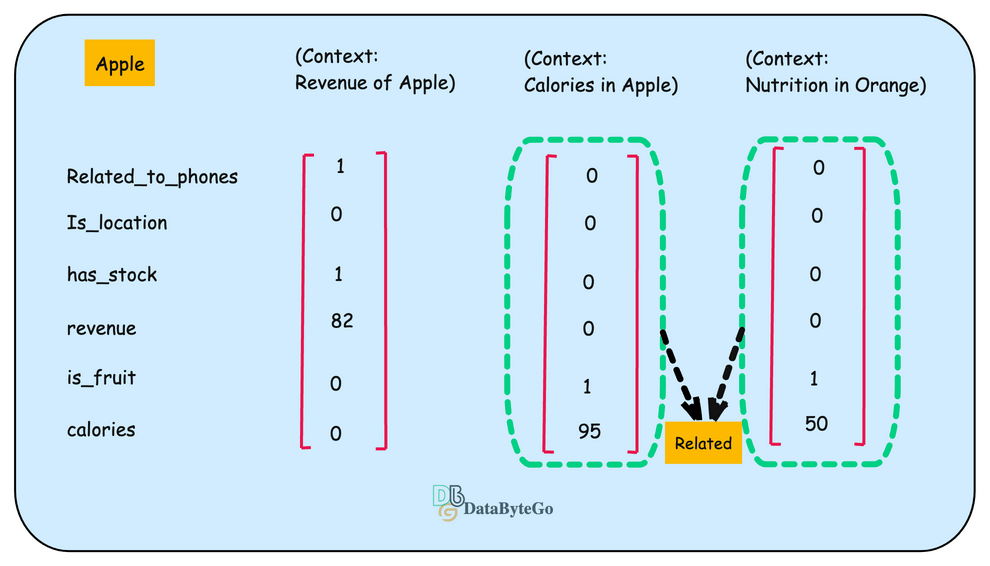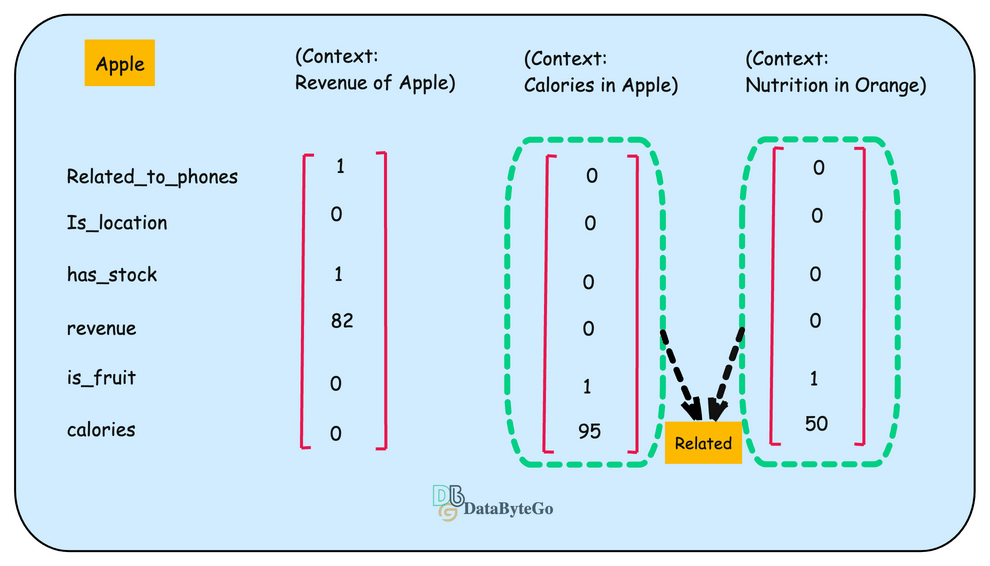
Now let's add another example of Company Samsung and create its numeric example.
if you compare the properties of of Apple(first) and Samsun(last), it looks similar.
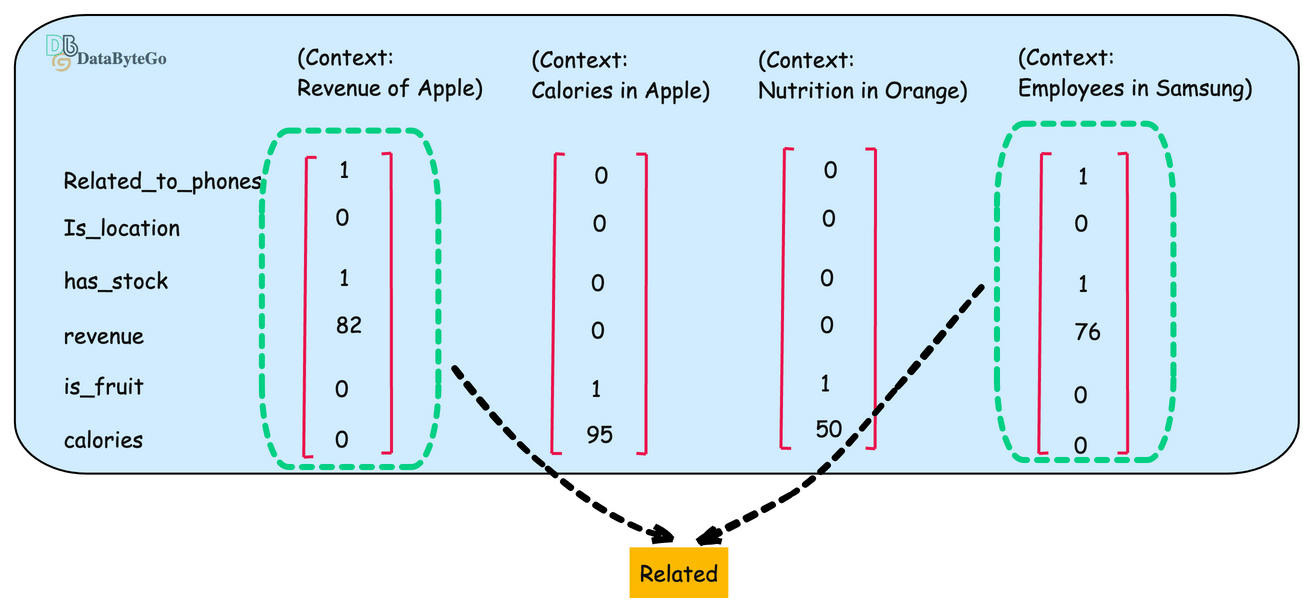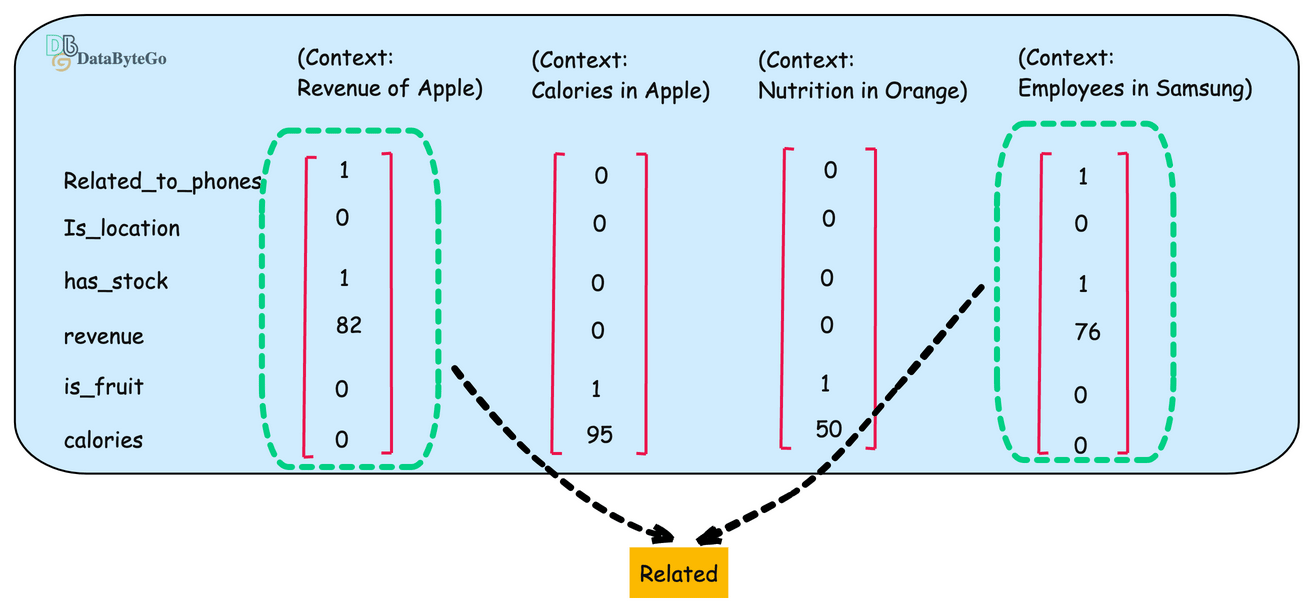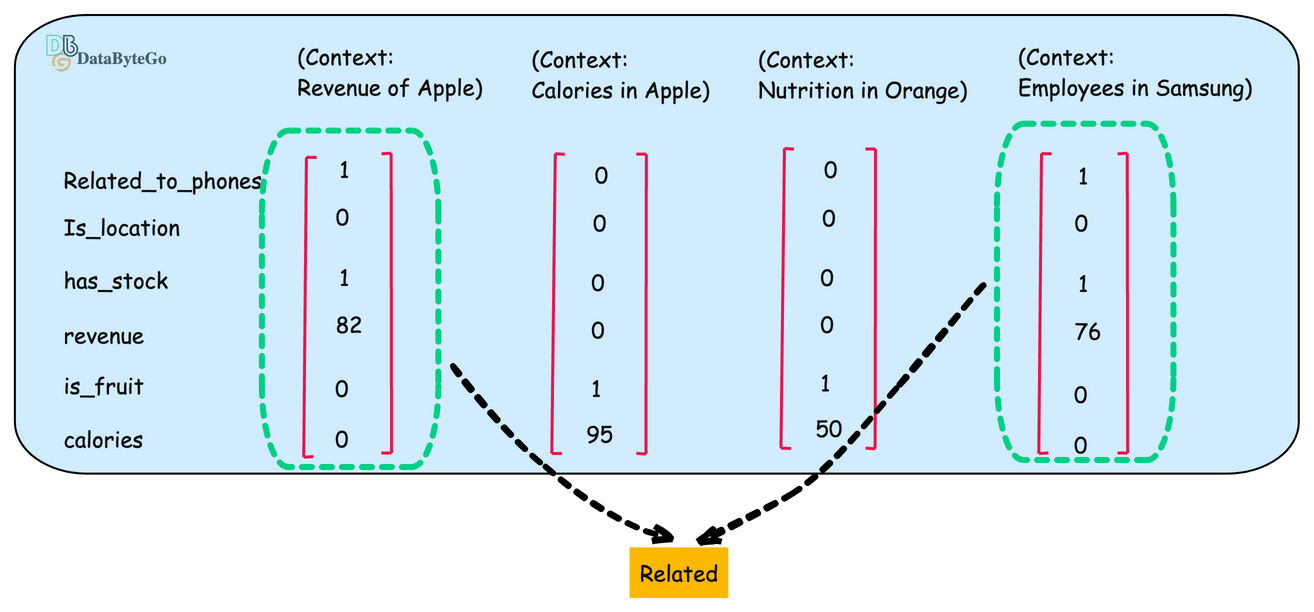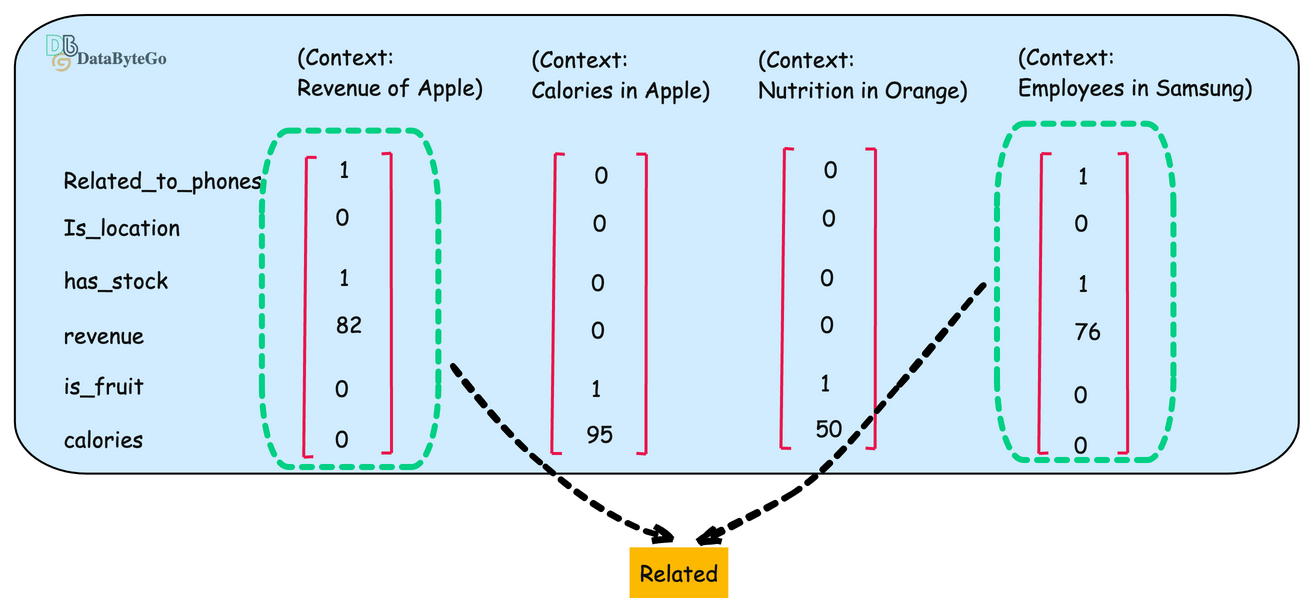
Now we can determine similarity using the vector. If you're developing a text-based AI application, you may have thousands or millions of embedding vectors that need to be stored somewhere.
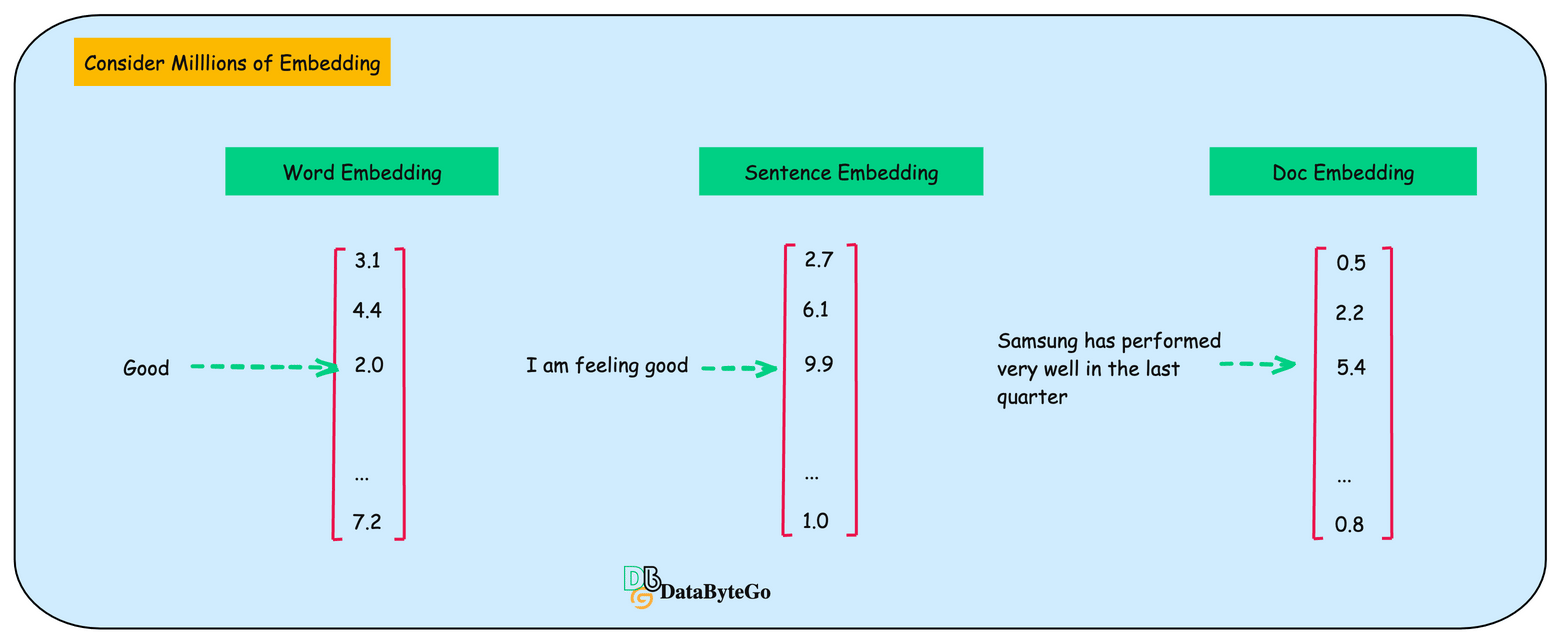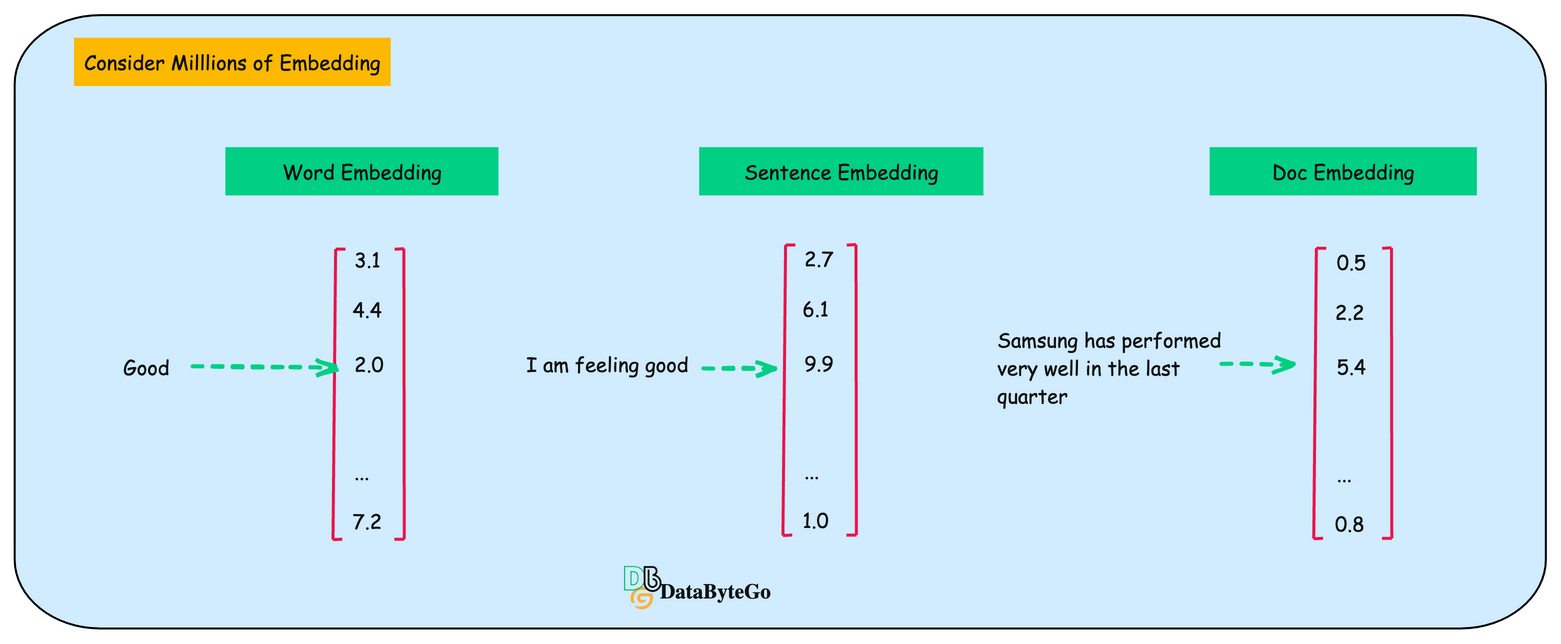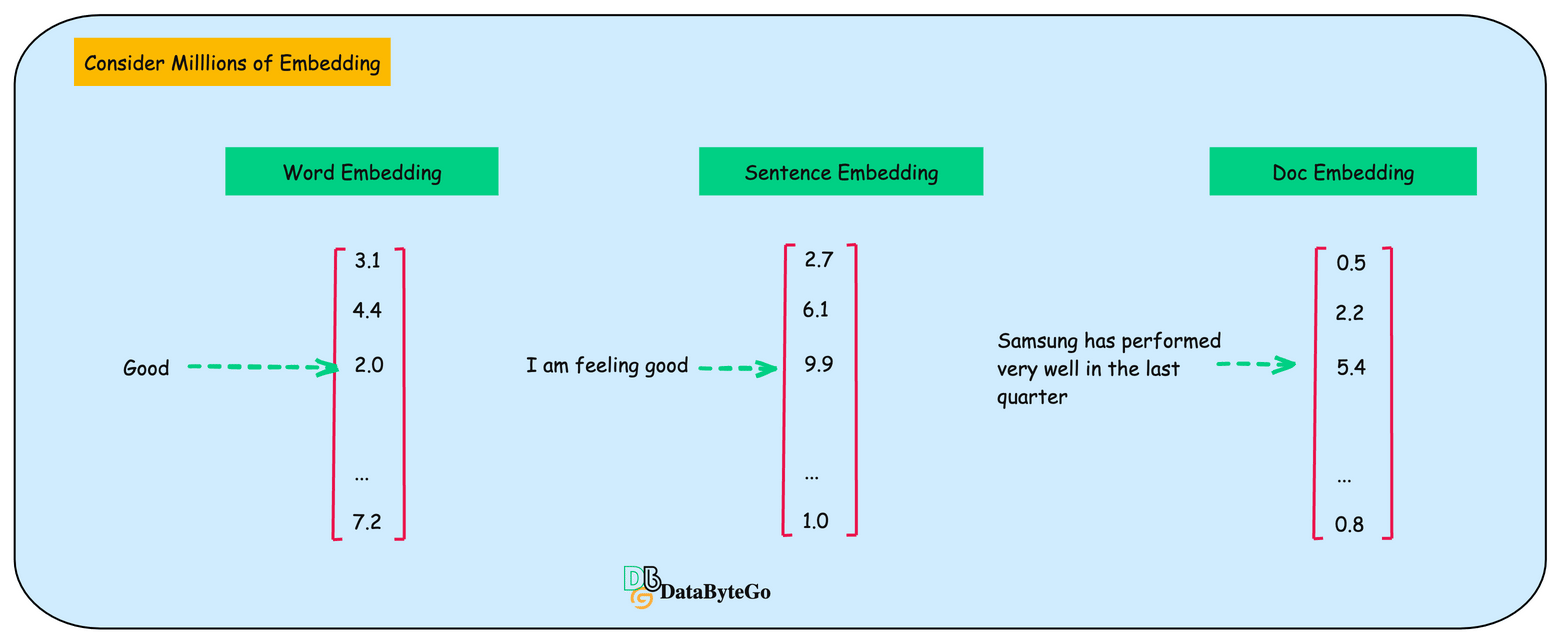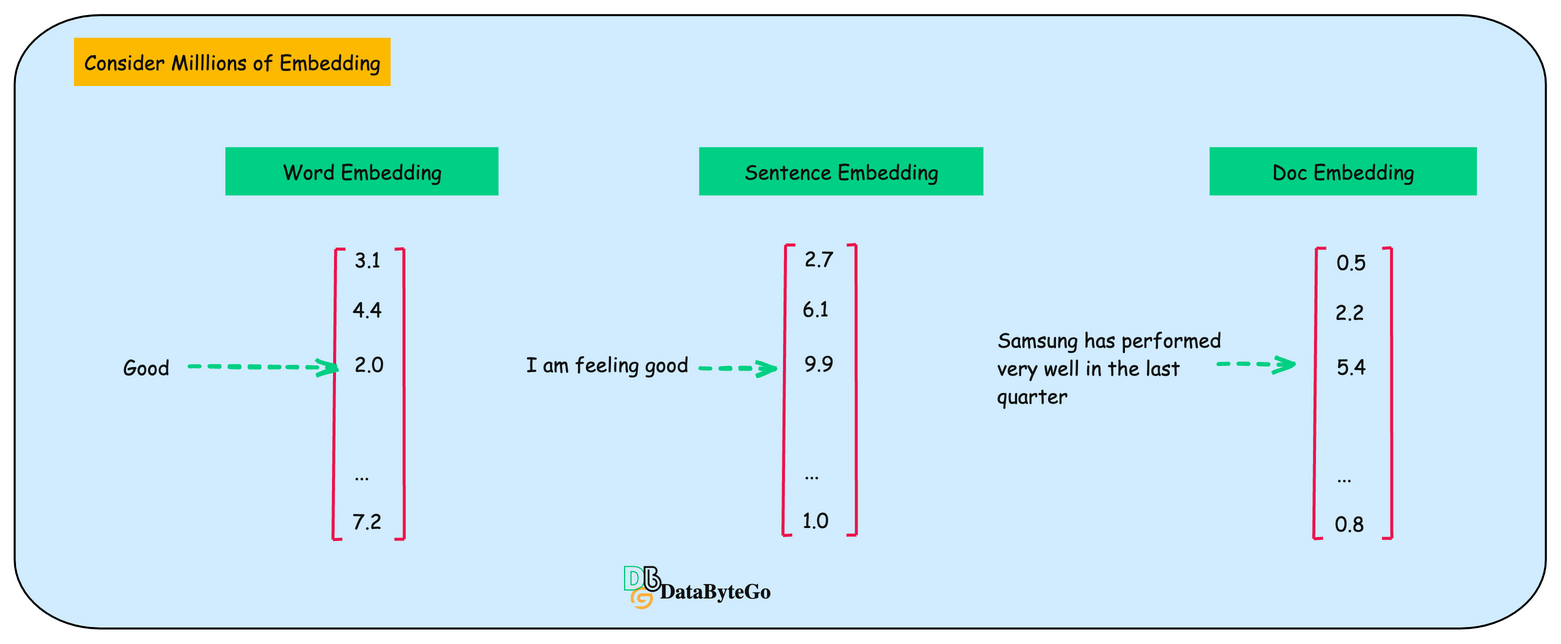
Why are relational databases not the best option for storing embedding or vectors?
The first option that comes to our mind is the traditional relational database management system(RDBMS, like PostgreSQL, Oracle, MySQL etc)
Let’s use an example of " Apple" with different context
Convert the document into embedding and store it in the Relational database, like MySQL and PostgreSQL.

When you have a search query, you will generate embedding for that and will try to compare the embedding with store data embedding and retrieve the relevant data embedding.
Here, we will use a concept of cosine similarity to get the matching vector and get the Google search result.

This, in theory, worked really well. However, in reality, the data will have millions of data embeddings stored in the database, and it will be very time-consuming to get the relevant matching record from the Relational database.
One of the approaches, in this case,, you will "Cosine similarity" be using is linear search. It will be going one by one, comparing the results and retrieving them.
Do you realize the problem now?
To receive the result of the entire string, the computation will be too much. Delay and $$$ inefficient.
Now think about - categorizing and grouping(buckets) the similar-looking embedding in the database by using a hashing function.
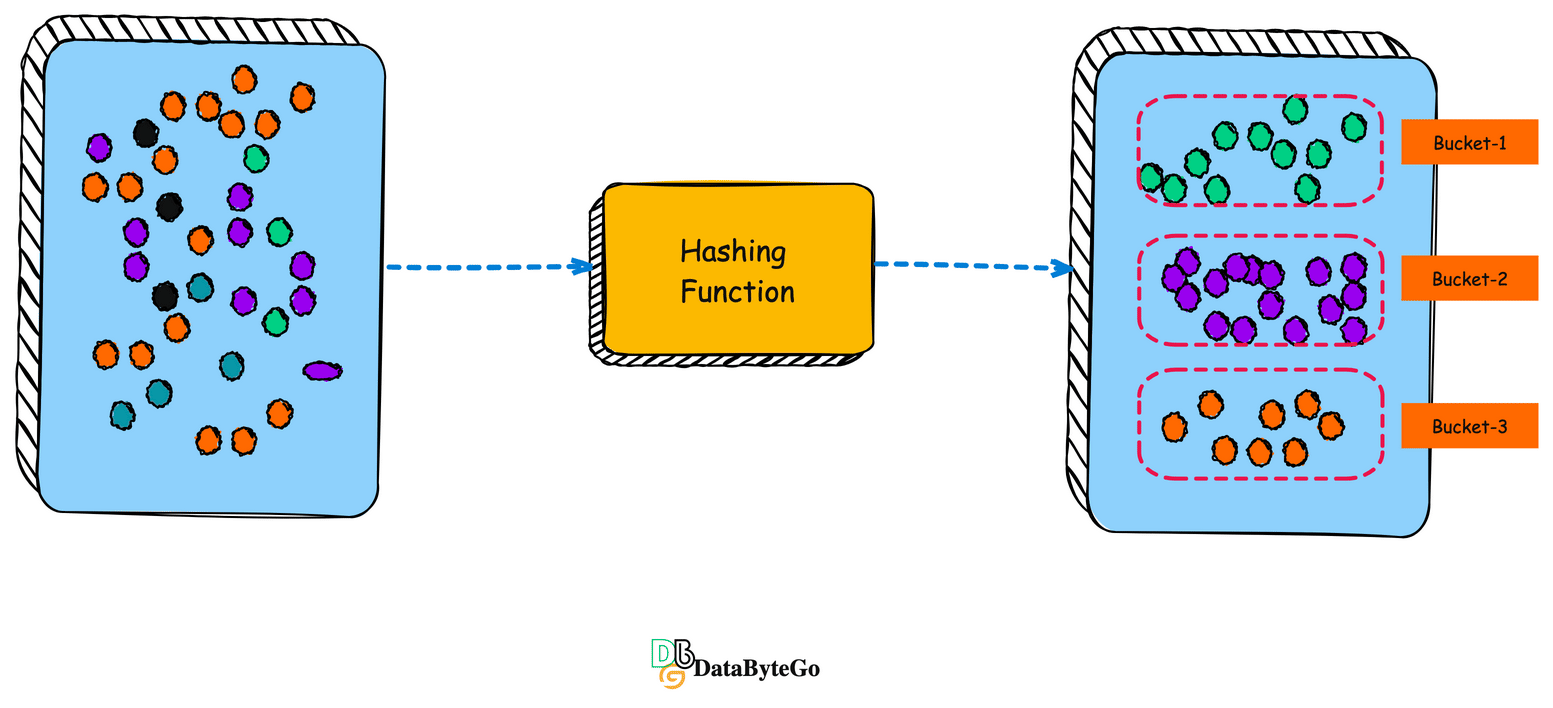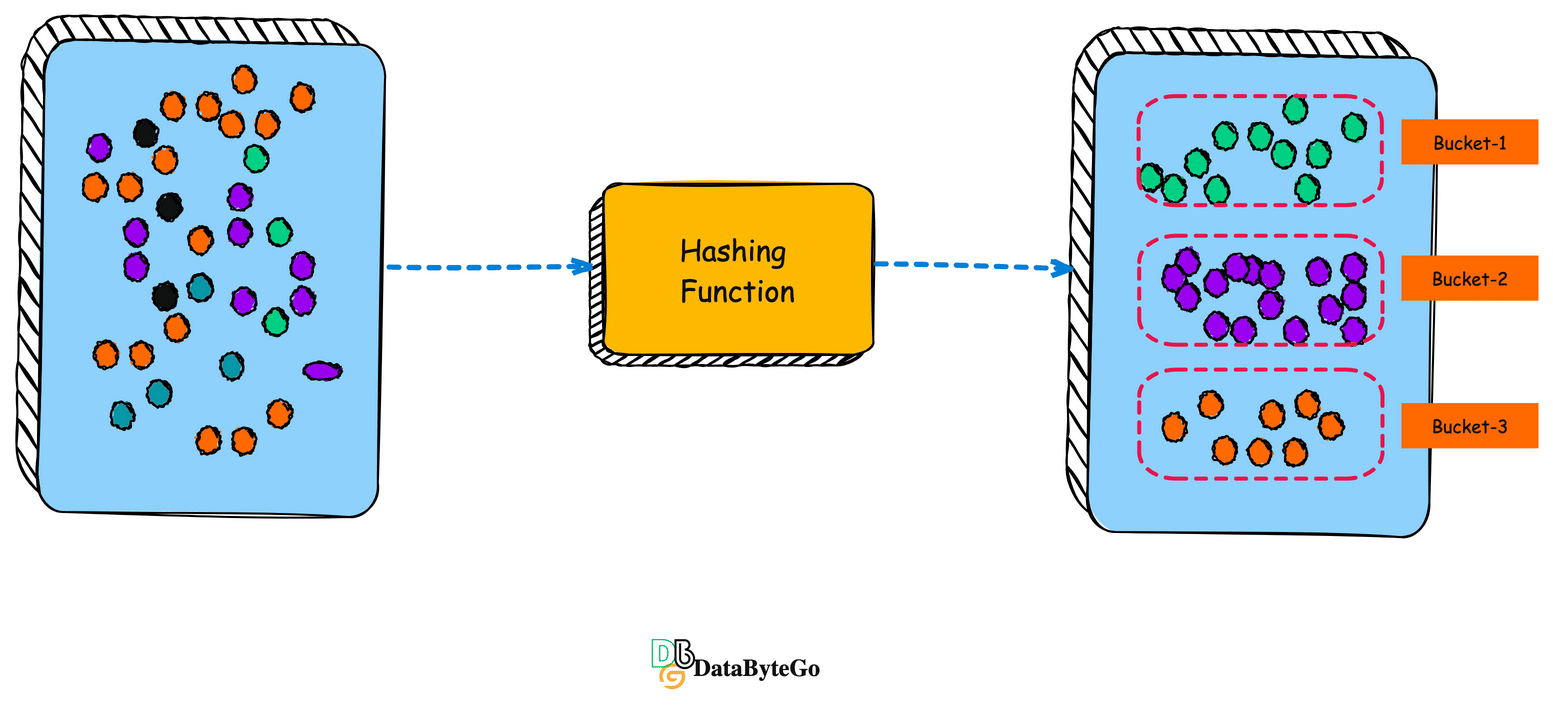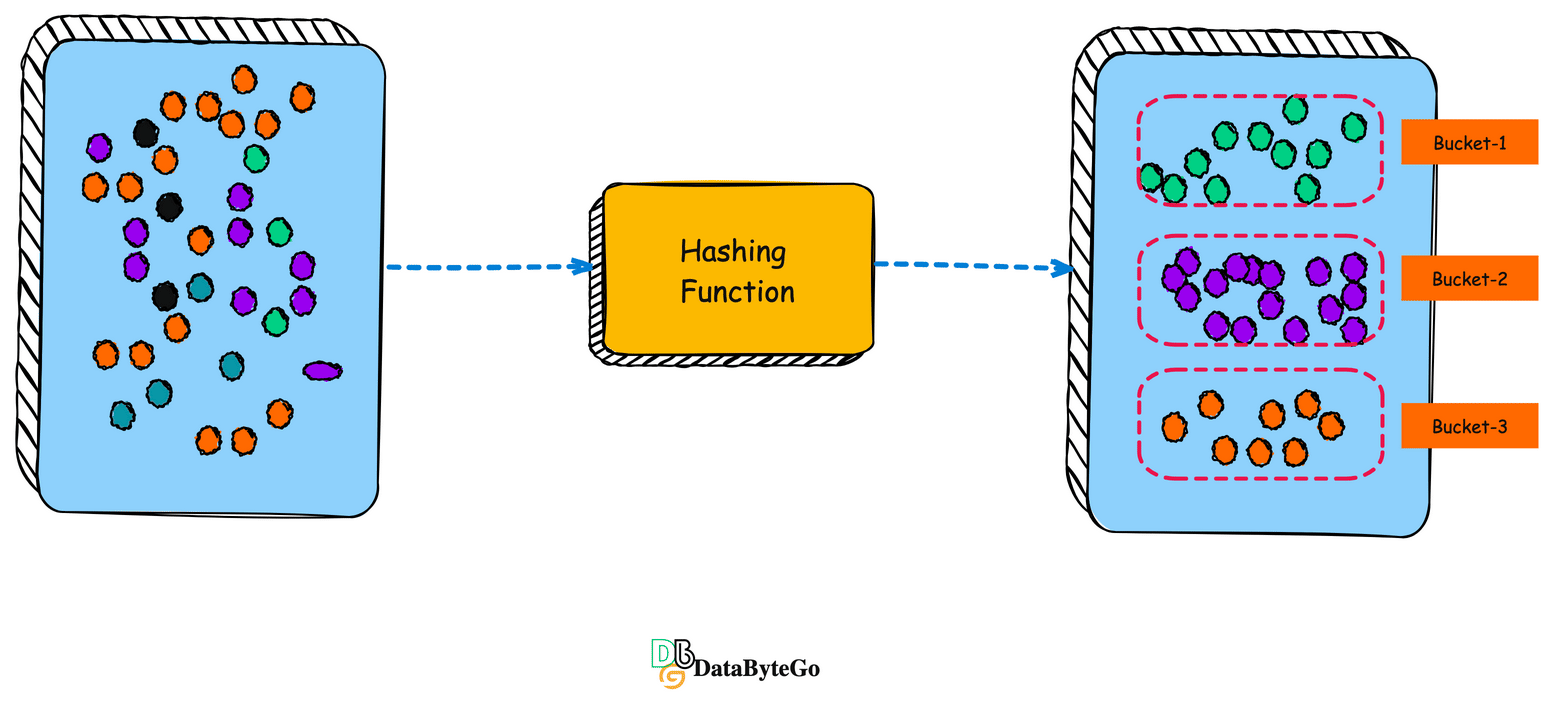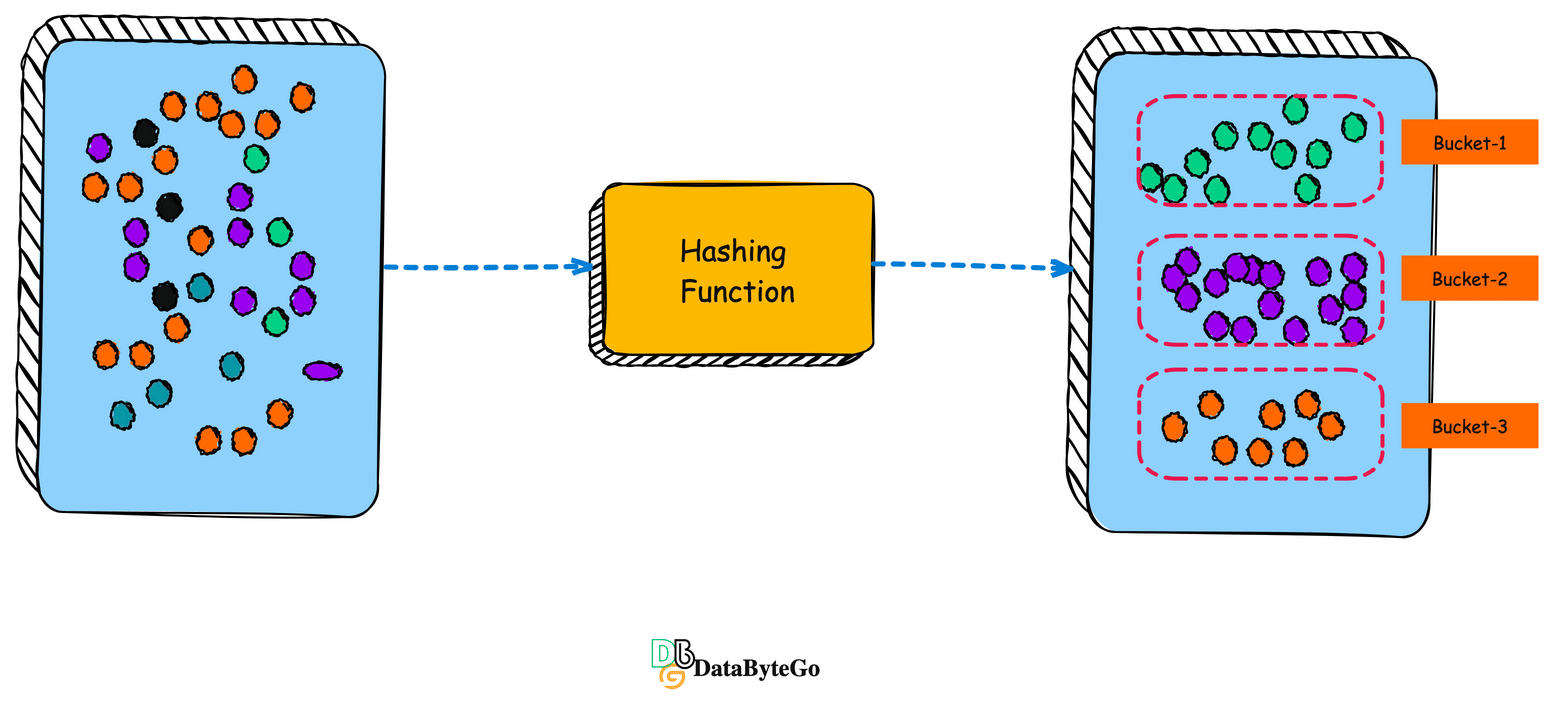
Now, when you have a search query, you can let the query go through the same hashing function, and then it will find the right bucket, and then within that bucket matching the embedding, the relevant embedding.
This way, you are only matching the search embedding in a single bucket and not the entire database.
This technique will help speed things up, and it’s called Locality Sensitive Hashing(LSH)
In Summary
Vector databases are helping AI-based applications due to their ability to handle high-dimensional data and perform similarity searches.
They enable advanced data processing and personalized experiences across various applications.
Businesses and AI applications can rely on vector databases for recommendation systems, search engines, anomaly detection, and personalized medicine.
Vector databases organize, index, and query complex data like images, text, and sensor readings.
Please feel free to read my blogs related to Data
Database Landscape" What Are the Different Types of Databases? (Part-1)
The Importance of Data Governance and Data Security in Modern Organizations