
Database Landscape" What Are the Different Types of Databases? (Part-1)
Learn about different type of database and their use case

What are databases?
Databases are organized collections of data, typically stored and accessed electronically from a computer system. They allow for the efficient storage, retrieval, and manipulation of data. Databases support various operations, including querying, updating, and administration of the data they contain. They are foundational to many software applications and systems, ranging from simple systems like contact management in phones to complex ones like high-traffic websites and banking systems.
The management of databases is done through a Database Management System (DBMS), which can be either relational (SQL) or non-relational (NoSQL), each suited to different kinds of data and use cases.
Database Trends
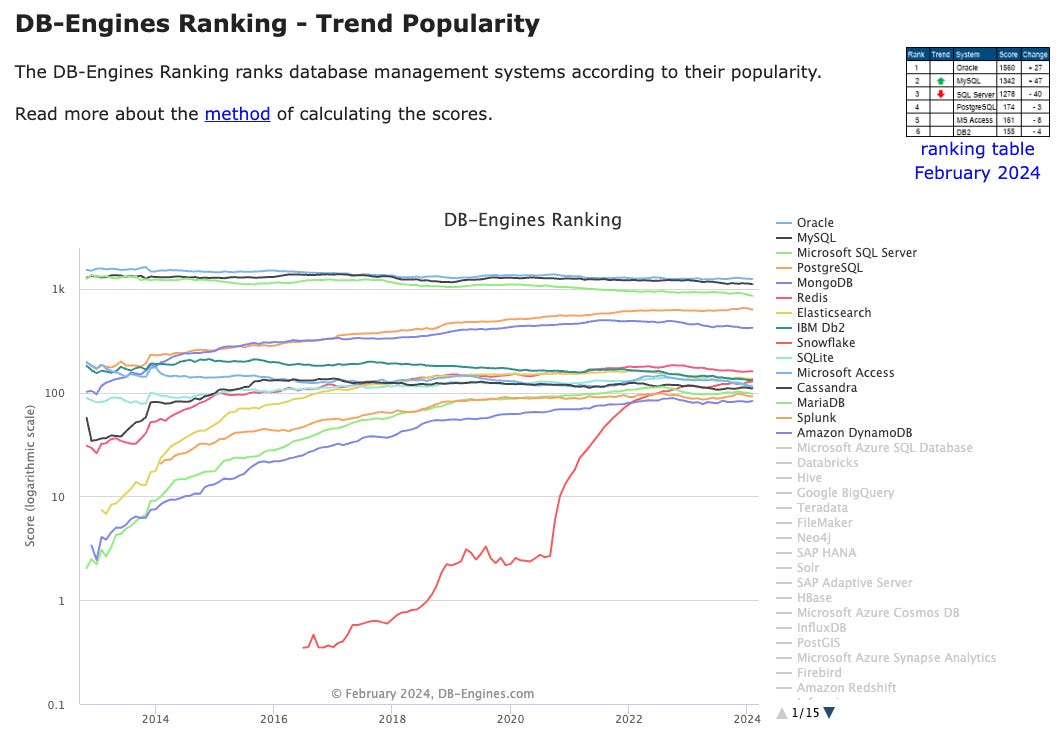
https://db-engines.com/en/ranking_trend
Let’s focus on the type of database available in the market:
1. Relational Database
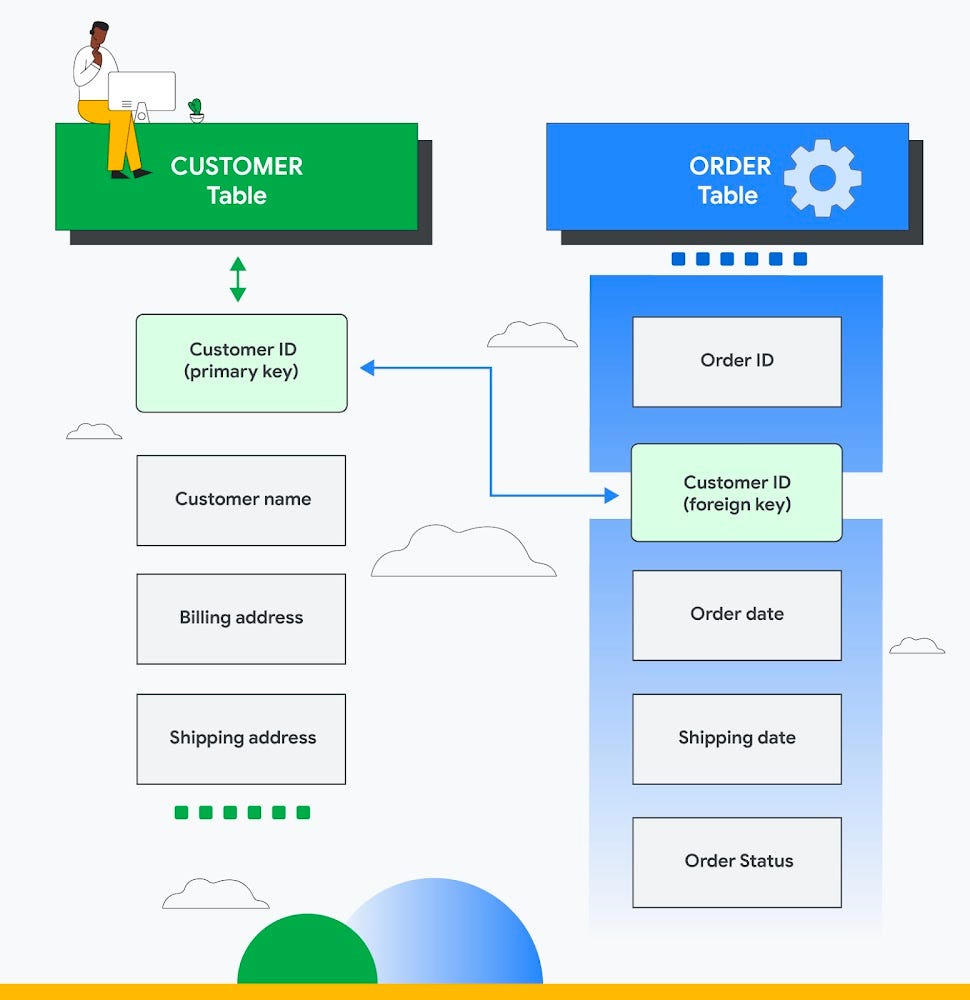
A relational database is a digital database based on the relational model of data, as proposed by E.F. Codd in 1970.
This model organizes data into one or more tables (or "relations") of columns and rows, with a unique key identifying each row.
Rows are also called records or tuples.
Columns are also known as attributes.
Each table/relation represents one "entity type" (such as customer or product).
The rows in the table represent instances of that type of entity (such as "John Doe" or "Widget A") and the columns representing values attributed to that instance (such as address or price).
Relational databases use Structured Query Language (SQL) for defining and manipulating data, which is very powerful. SQL is an ANSI and ISO standard, and is used by most of the relational database systems. The use of SQL is a major factor in the widespread adoption of relational databases.
These databases are highly flexible, allowing users to create, modify, and query data in a variety of ways. Data integrity is ensured through the use of rules such as primary keys, foreign keys, and constraints which enforce relationships between tables and assure that data is consistent and accurate. This makes relational databases ideal for handling structured data, where relationships between different data types need to be clearly defined.
PostgreSQL: Known for its advanced features, extensibility, and standards compliance.
MySQL: Widely used for web applications, particularly those running on a LAMP (Linux, Apache, MySQL, PHP/Python/Perl) stack.
Oracle Database: Preferred in enterprise environments for its robust feature set and scalability.
Microsoft SQL Server: Commonly used in enterprise environments, especially those with other Microsoft technologies.
SQLite: Embedded into the end program, popular for applications like mobile apps or games.
IBM Db2: Often used in enterprise settings, particularly for high-volume data and transaction processing.
MariaDB: A fork of MySQL, known for being open-source and community-developed.
SAP Sybase ASE: Used primarily in financial industries for its performance and stability.
2. NOSQL Database:
A NoSQL database provides a mechanism for storage and retrieval of data that is modeled in means other than the tabular relations used in relational databases. These databases are often used for large data sets or for real-time web applications. NoSQL databases are varied in types, including document-oriented databases, graph databases, key-value stores, and wide-column stores. They are chosen for their flexibility with unstructured data, scalability, and performance in specific use cases like big data applications. Unlike relational databases, NoSQL databases don't require a fixed schema, allowing data to be stored in various formats.
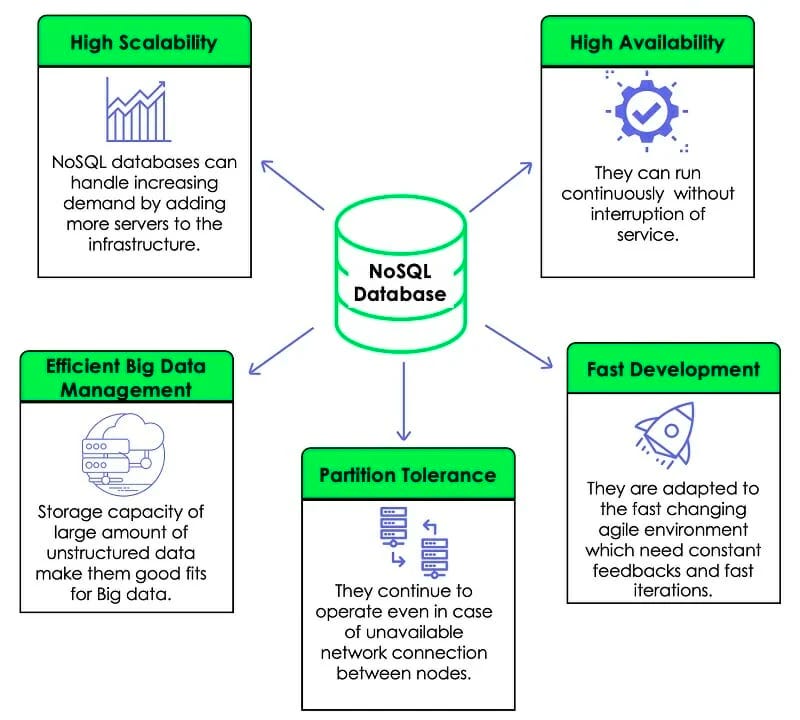
Source: DataCamp
Document-Oriented Databases: These store data in documents similar to JSON or XML. Each document contains semi-structured data that can be queried. This type is useful for content management systems and e-commerce applications.
Key-Value Stores: They are the simplest form of NoSQL databases, storing data as a collection of key-value pairs. This type is highly scalable and suitable for applications that require high-speed for reading and writing data.
Wide-Column Stores: Organize data into tables, rows, and dynamic columns. They are efficient for analyzing large datasets and are suitable for real-time analysis and high-speed transactions.
Graph Databases: Designed for data whose relations are best represented as a graph and has elements interconnected with an undefined number of relations. This type is ideal for social networks, fraud detection systems, and recommendation engines.
3. Time Series Database
A Time Series Database is specialized for handling time-series data, which are data points indexed in time order. This type of database is optimized for storing and serving large amounts of time-stamped data, like data collected from sensors, network devices, financial systems, and other sources that generate data over time. Time series databases are efficient for time-based querying and analysis, handling time-stamped data that changes or is updated over time. They are commonly used in monitoring systems, IoT applications, financial market data analysis, and other areas where tracking the change and trend of data over time is critical.
What are the popular time-series databases?
Prometheus (CNCF project) - is an open-source monitoring solution used to understand insights from metrics data and send necessary alerts. It has a local on-disk time-series database that stores data in a custom format.
InfluxDB - is an open-source time-series database, with a commercial option for scaling and clustering.
TimescaleDB - is an open-source relational database that makes SQL scalable for time-series data. This database is built on PostgreSQL.
Graphite - All-in-one solution for storing and efficiently visualizing real-time time-series data. Graphite can do two things, store time-series data and render graphs on demand. But it doesn’t collect data for you; for that, you can use tools such as Collectd, Ganglia, Sensu, Telegraf, etc.
CrateDB - is an open-source + licensed version of the distributed SQL database for relational and time-series data.
GridDB - is a highly scalable, in-memory NoSQL time-series database optimized for IoT and Big Data.
M3DB - is an open-source metrics platform and distributed time-series database. It is compatible with Prometheus and Graphite.
OpenTSDB - is a distributed, scalable TSDB written on top of HBase.
4. NewSQL databases
NewSQL databases are a class of modern relational database management systems that seek to provide the same scalable performance of NoSQL systems for online transaction processing (OLTP) workloads while maintaining the ACID guarantees of a traditional database system. They are designed to address some of the scalability issues of traditional SQL databases without sacrificing the strong consistency, durability, and transaction capabilities that SQL databases provide. NewSQL databases are particularly useful in environments where high performance, scalability, and data integrity are critical, such as in financial trading systems or online retail applications. They often employ distributed architectures and innovative techniques to achieve these goals.
The main features of NewSQL databases are:
In-memory storage and data processing supply fast query results.
Partitioning scales the database into units. Queries execute on many shards and combine into a single result.
ACID properties preserve the features of RDBMS.
Secondary indexing results in faster query processing and information retrieval.
High availability due to the database replication mechanism.
A built-in crash recovery mechanism delivers fault tolerance and minimizes downtime.
Reference: NewSQL Database assessment https://www.mdpi.com/1999-5903/15/1/10
VoltDB
VoltDB works well with high-speed transactional applications. The database performs in-memory processing on a distributed architecture. The software is available as both open source and proprietary.
Key features:
Real-time decision-making.
Support for Kafka import and export.
Disaster recovery through database replication.
Hadoop and OLAP export integration.
2. CockroachDB
CockroachDB is a scalable and robust database. The database offers strong data consistency and works well with low-latency resources.
Key features:
Robust disaster recovery system.
Historical data view, record, and storage options.
Built-in cleaning processes for disks and storage devices.
CockroachDB works in unfavorable conditions.
NuoDB
NuoDB is a geo-distributed database with flexible scaling for various geographic locations. The database maps data across various points while staying ACID compliant.
Key features:
High-quality data transformations.
Always available with online schema evolutions and rolling upgrades.
Tailored features for data storage and control.
Full ACID transaction support.
ClustrixDB
ClustrixDB is a self-managing NewSQL database. The software automates scaling operations and supports high availability.
Key features:
Efficient data categorization.
SQL code migration options.
Built-in health metrics in a browser interface.
DevOps assistance and query caching.
Altibase
Altibase is an in-memory database with a hybrid architecture. The database reduces hardware and software costs by combining in-memory data processing with an on-disk DBMS with a single license. Altibase comes in both community and proprietary versions.
Key Features
Memory-optimized engine for increased speeds.
Custom persistence and performance balance levels.
Flexible deployment options.
Real-time access to vital data.
In part-2 I am going to cover rest of the database types and examples.