
[AI/LLM Series] Building a Smarter Data Pipeline for LLM & RAG: The Key to Enhanced Accuracy and Performance
Want to get the most out of your LLM and RAG systems? It all starts with a solid data pipeline. In this guide, we’ll break down how simple techniques like chunking and cleaning your data can boost acc

Key Takeaways
Breaking data into chunks helps RAG systems work better. By splitting large datasets into smaller, manageable pieces, RAG systems can process information more accurately and provide relevant responses for search.
Clean data is key to getting good results. RAG systems rely on clean, well-organized data to deliver reliable answers. Messy or inconsistent data can lead to mistakes or irrelevant information.
Poorly chunked or unclean data hurts performance. If data isn’t properly chunked or cleaned, RAG systems might return incomplete, confusing, or inaccurate results, which can frustrate users.
A well-structured data pipeline makes all the difference. Having a smooth process for organizing and cleaning data ensures RAG systems run efficiently, leading to better insights and overall user experience.
Today, every organization is turning to artificial intelligence (AI) not only for its products and offerings but also to boost productivity and streamline Operations. According to IBM’s, AI is making significant strides in customer service, talent management, and modernizing applications. For instance, AI can handle up to 70% of contact center cases, improving the customer experience by providing faster and more accurate responses. In HR, AI-powered solutions are boosting productivity by 40%, making tasks like candidate screening and employee training more efficient. Additionally, AI is enhancing application modernization by 30%, reducing the workload in IT operations through automation, such as handling support tickets and managing incidents.
Source: https://www.ibm.com/think/topics/generative-ai-for-knowledge-management
How are organizations making it happen?
One of the most impactful applications of AI is Retrieval-Augmented Generation (RAG), which combines the power of Large Language Models (LLMs) with real-time data retrieval. This combination is reshaping how businesses operate, helping them respond more quickly, make better decisions, and deliver improved customer experiences.
Tip: Learn about What’s RAG and how it works: https://www.databytego.com/p/aiml-brief-introduction-to-retrieval
Some of the most common examples and use cases of RAG(and LLM) in organizations are
Customer Support: Automates responses by retrieving answers from knowledge bases for faster customer service.
Sales and Marketing: Generates personalized marketing content using customer data and market trends and identifying the most qualified customer based on certain behavior.
Legal and Compliance: Analyzes contracts by retrieving key clauses and providing summaries or risk assessments.
Research and Development: Retrieves and synthesizes information from patents and scientific papers to guide innovation.
Financial Services: Produces detailed risk assessments by analyzing financial reports and market data.
What does a typical RAG Pipeline look like?
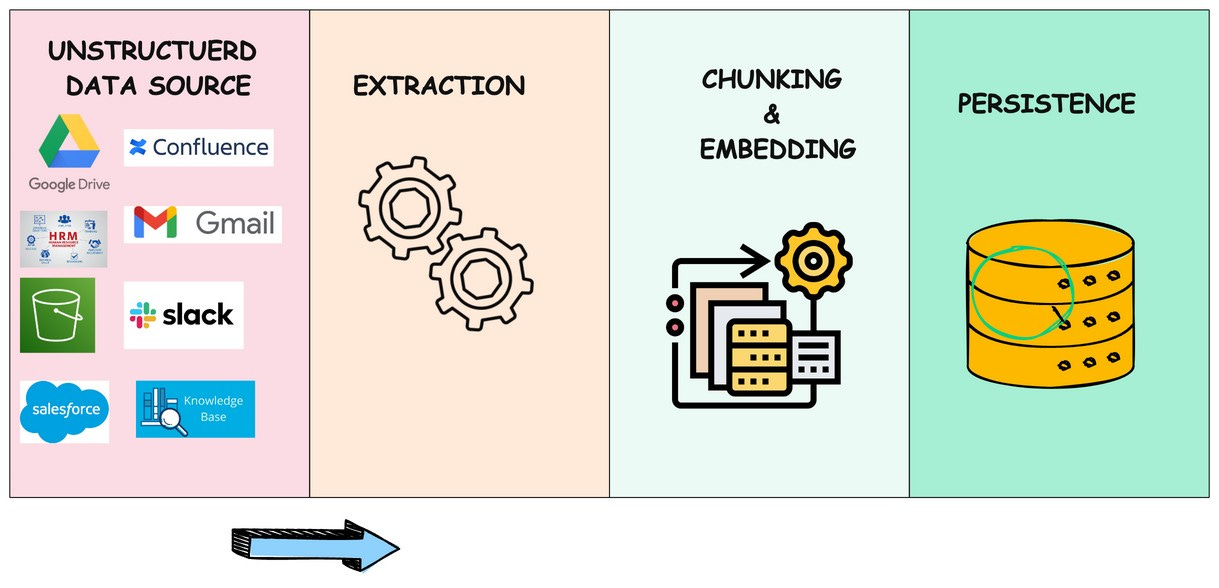
This is what a typical RAG pipeline looks like in any enterprise. Each dotted box represents either a use case or the Project in the organization.
Company→ BU/Deparments → Use cases → Projects → Pipelines
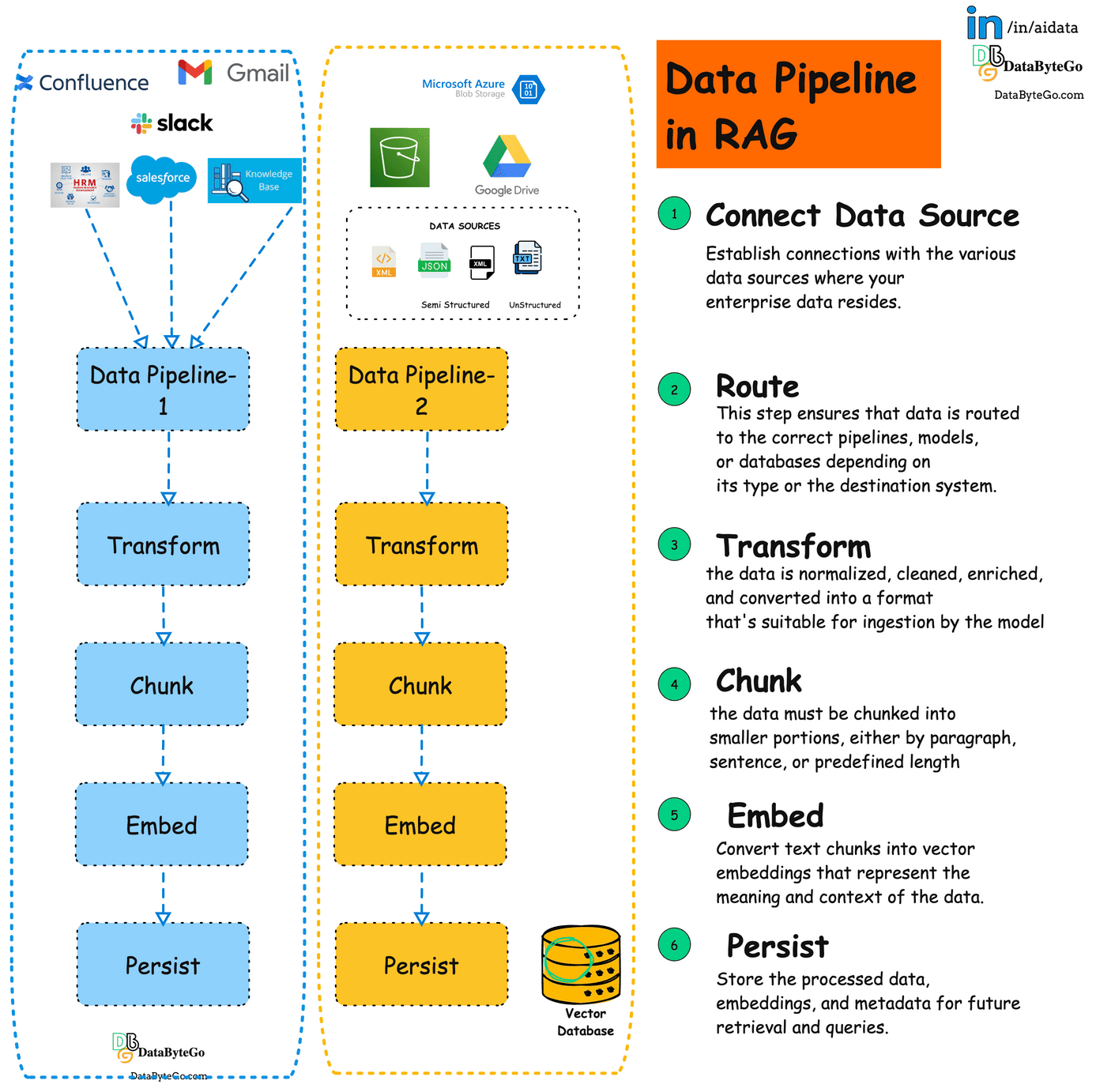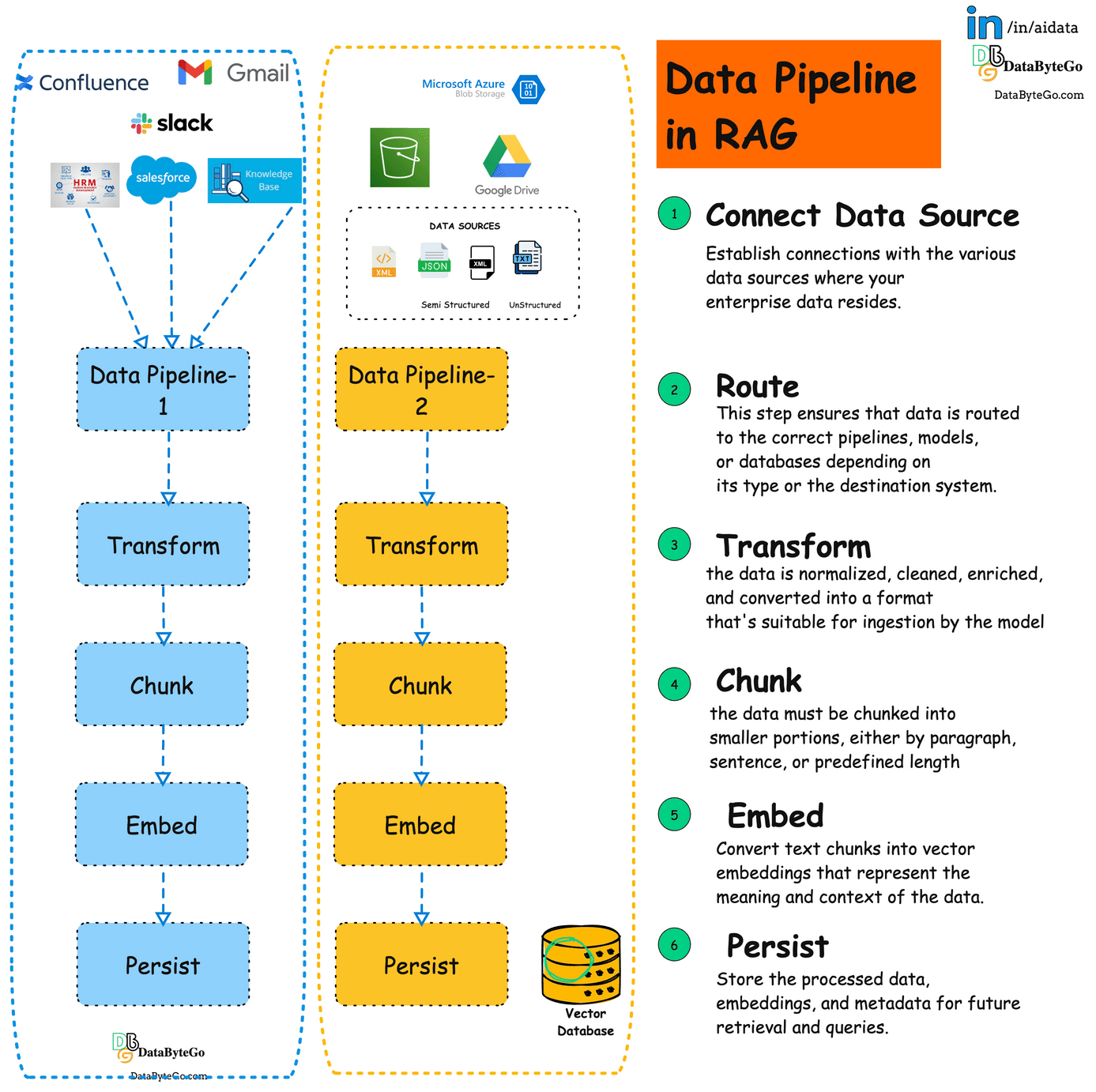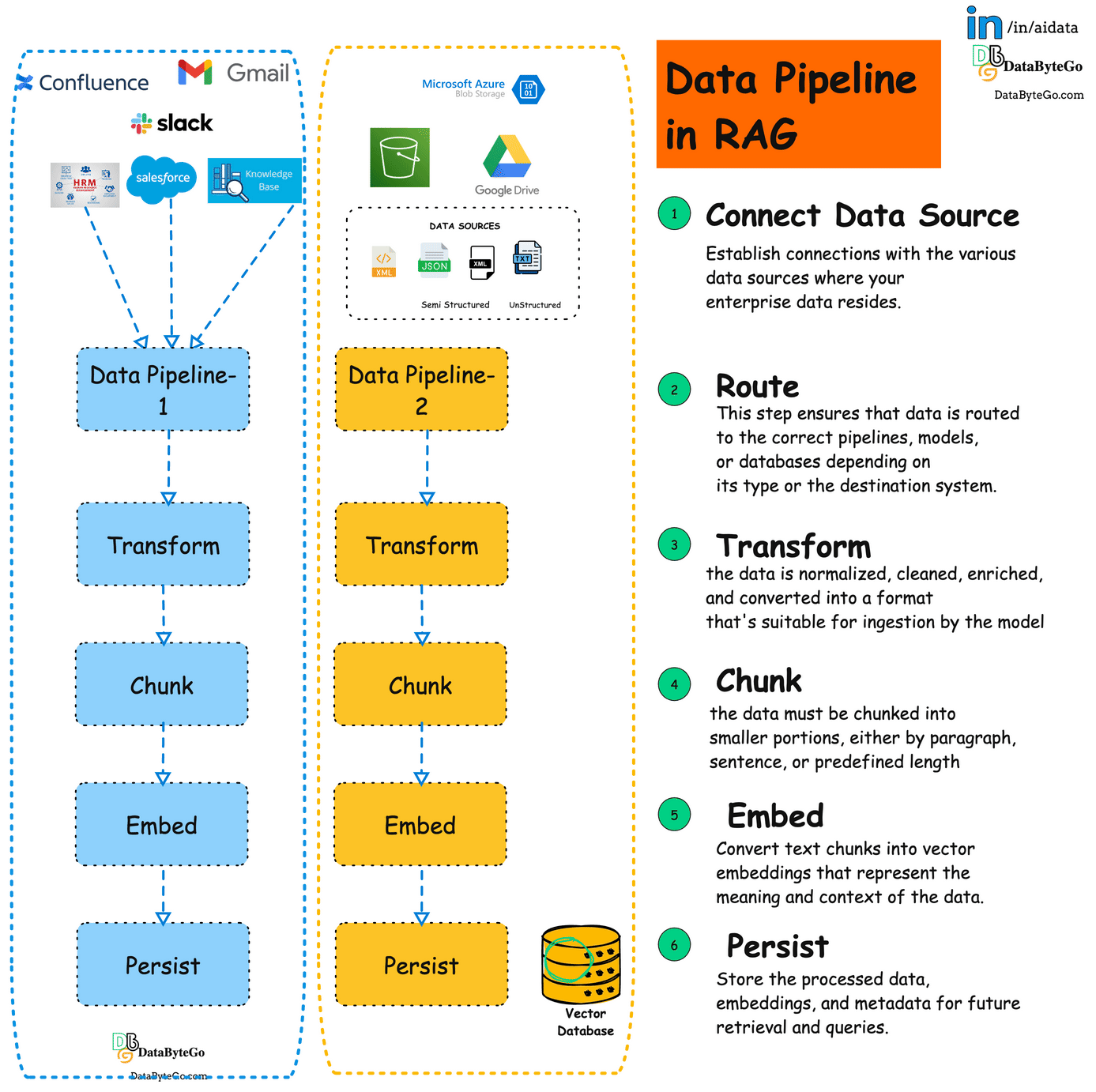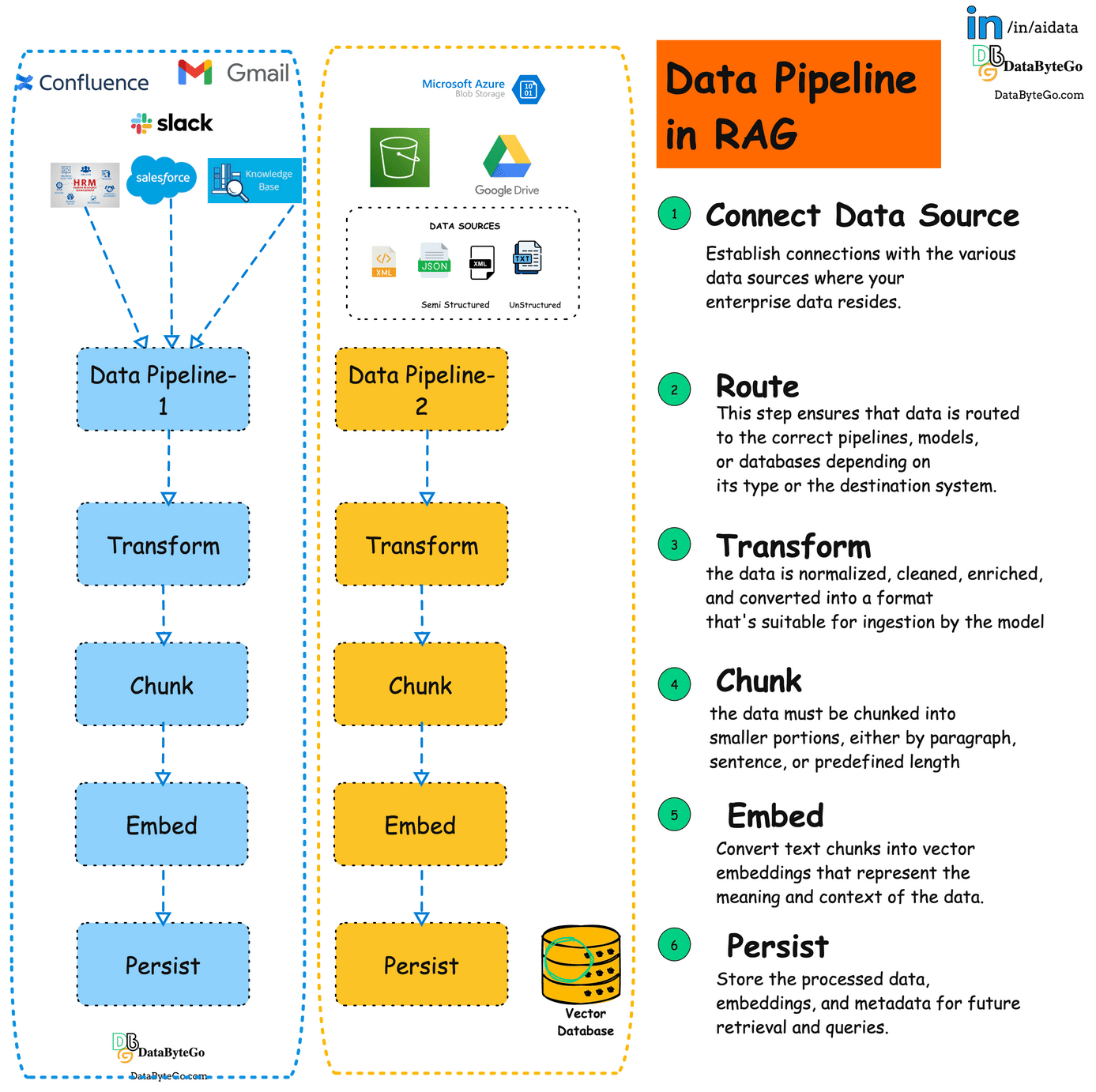
Connect Datasource:
Establishes connections with various data sources like databases, file storage, and internal apps.This Enables pulling relevant data to feed the RAG model.Route:
Directs the data from the sources to the appropriate downstream processes. This ensures the right data reaches the correct models or systems for optimized flow.Transform:Cleans, standardizes, and prepares data for use in machine learning workflows. This helps ensure consistent, clean data for accurate model results.
Chunk:Breaks large datasets into manageable pieces, suitable for LLM processing.This allows the model to process data without exceeding context limitations.
Embed:Converts text chunks into vector embeddings for semantic search and data retrieval. Embeddings make data searchable based on meaning, improving query results.
Persist:Stores processed data and embeddings for future queries in a vector database or data lake. This ensures fast and efficient retrieval when needed for RAG workflows.
The problem of Creating a Bad Data Pipeline for RAG
On the other hand, a poorly constructed data pipeline can severely undermine the performance of RAG systems. With a reliable pipeline, data ingestion might be consistent, leading to gaps or outdated information. If the data is not properly cleaned or preprocessed, it can introduce noise, biases, or errors into the system, resulting in inaccurate or irrelevant outputs. This could be particularly damaging in enterprise applications where precision and reliability are critical, such as in legal document analysis, financial forecasting, or medical research.
A poorly designed data pipeline can cause problems like inconsistent data flow, wrong information, or slow responses. This makes the RAG (Retrieval-Augmented Generation) system less useful. If the pipeline doesn't clean or organize the data well, the system may provide confusing or incorrect answers, frustrating users and requiring more manual fixes.
Example: Customer Support
Imagine a company using RAG to answer customer service questions. If the pipeline doesn't clean up the data—removing things like special characters or outdated information—the system might provide messy or irrelevant responses. For example, if a customer asks, "How do I update my shipping address?" but the system pulls outdated instructions or includes strange characters in its response, it could confuse the customer and lead to frustration.
This kind of bad pipeline can also make the system slower, causing delays in answering questions, which could reduce the trust customers have in the company’s support service.
Example: Research and Development
In a research and development team, an RAG system might be used to summarize scientific papers and patents. If the data pipeline is poorly designed, it could fail to properly segment the text into meaningful chunks or remove irrelevant formatting. For instance, if the system tries to summarize a paper but the data is jumbled with incorrect citations or non-standard characters, the summaries might be misleading or incomplete. This can hinder the research process, slow down innovation, and lead to incorrect conclusions.
Learn more about RAG use cases here https://hyperight.com/7-practical-applications-of-rag-models-and-their-impact-on-society/
Why Data Chunking and Data Cleaning Are Crucial for RAG Systems
When using Retrieval-Augmented Generation (RAG) technology, having high-quality data is essential for getting accurate and helpful results. Two key processes that help ensure this quality are data chunking and data cleaning.
Data Chunking: Making Information Manageable
Breaking up is hard to do: Chunking in RAG applications
https://stackoverflow.blog/2024/06/06/breaking-up-is-hard-to-do-chunking-in-rag-applications/
Data Cleaning: Keeping Information Accurate
Data chunking means breaking down large amounts of information into smaller, easier-to-handle pieces. This helps the RAG system process data more effectively.
Imagine you’re using a customer support system to find information in a long product manual. If the manual is divided into clear sections—like setup instructions, troubleshooting, and warranty info—the system can quickly find and provide the right details when a customer asks for help. Proper chunking helps the system avoid getting overwhelmed and ensures it gives precise answers.
Data cleaning involves fixing mistakes and removing unnecessary or confusing information from the data. This is important because clean, accurate data helps the RAG system give reliable responses.
For example, if a legal compliance system is analyzing contracts, and the data includes strange symbols or outdated sections, the results might be incorrect or confusing. Cleaning the data—by removing errors, fixing formatting issues, and standardizing the text—makes sure the system delivers clear and correct information.
Thank you for reading through this blog. I hope you have learned something new and interesting.
Considering the details, Depth, and insights on this topic, I will be publishing part-2
Why data chunking and Data Normalization matter?
Types of data chunking and data normalization techniques.
Detailed examples.