
PostgreSQL Performance and Tuning: How to Optimize Database for High Performance
Are you worried that your PostgreSQL database is not performing well? Are you able to figuure out what to look for and what is the right place to start? I am going to help resolve this piece by piece

Hello, and welcome to a free monthly edition of my newsletter. I’m Ajay, and each week I tackle reader questions about PostgreSQL, working and implementing PG with best practices, and anything else that’s stressing you out in PostgreSQL world. Send me your questions and in return, I’ll humbly offer actionable real-talk advice. 🤜🤛
If you find this post valuable, check out some of my other posts:
To receive this newsletter in your inbox weekly, consider subscribing 👇

Database performance is one of the most important and challenging aspects of being a database administrator, application developer or consultant. . A poorly performing database can lead to slow query times, poor user experience, and even loss of business.
PostgreSQL is a powerful database, but it can often be slow and sluggish. This can be frustrating for users who are trying to access data quickly.
There are many ways to optimize your PostgreSQL database for high performance. With the right tools and settings, you can dramatically improve the speed and responsiveness of your database.
In this guide, we'll show you how to use PostgreSQL tools to tune your database for high performance. We'll also provide tips on how to troubleshoot common performance issues. Considering this topic is going be very very detailed I am going to write the blog in consumable format rather than one big blog of 10000 words.
First, we will focus on “What are the factors that affect PostgreSQL performance” and areas we should be aware of.
In the second blog, we will cover all the parameters we should be looking at from the PostgreSQL side and on the Operating system side for better and faster performance.
Factors affecting PostgreSQL performance?
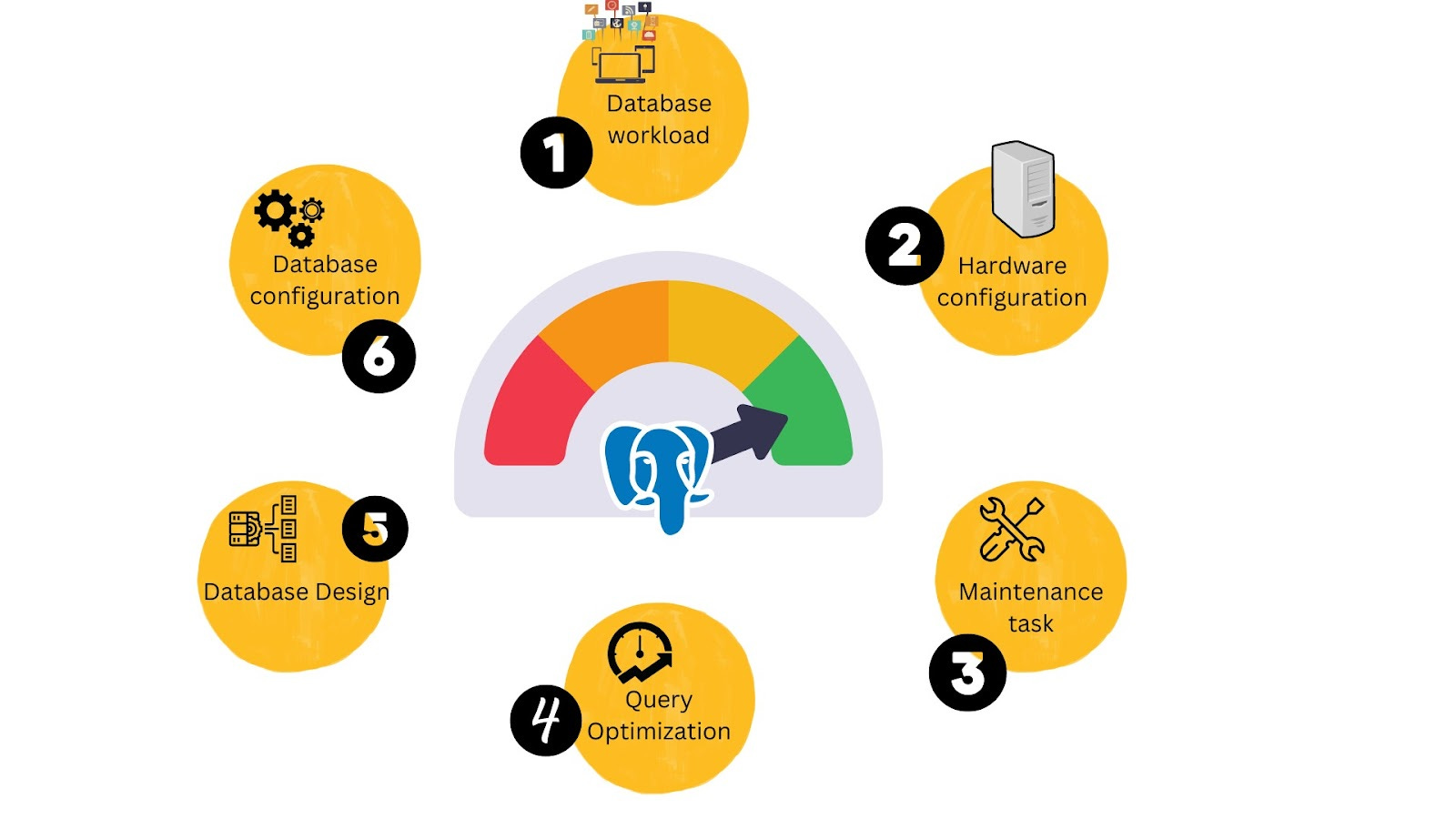
For simplicity - we are going to divide it into 6 categories
Database workload
Hardware configuration
Maintenance task
Query optimization
Database design
Database configuration
1. Database configuration
PostgreSQL configuration file contains a variety of settings that can impact the performance of the database server. It's important to understand the impact of each setting and to configure them appropriately to ensure that the server is using resources effectively. Regular monitoring and tweaking of the configuration settings can help to maintain optimal performance over time.
Among the most important settings for performance tuning are:
shared_buffers: controls the amount of memory that the server uses for caching data
max_connections: controls the maximum number of concurrent connections that the server will allow
effective_cache_size: used by the query planner to estimate the amount of data that is held in the operating system cache.
autovacuum_vacuum_scale_factor: controls the behavior of the autovacuum daemon
max_wal_size: controls the maximum size of write-ahead logs
checkpoint_timeout: controls the frequency of checkpoints
work_mem: controls the amount of memory used by the query planner for sorting and hashing operations
maintenance_work_mem: controls the amount of memory used by maintenance operations such as VACUUM and ANALYZE
random_page_cost: controls the cost of reading a random page from disk
wal_buffers: controls the amount of memory used for the write-ahead log
2. Hardware configuration
The hardware configuration factors that affect PostgreSQL performance are: memory, CPU, disk space, network
CPU: The number of CPU cores and their clock speed can affect the ability of the database server to process queries and perform other tasks. More cores and higher clock speeds can lead to faster query processing and better overall performance.
Memory: The amount of memory available to the database server can affect the performance of queries and other operations that rely on caching data in memory. Having enough memory to cache frequently accessed data can greatly improve performance.
Storage: The type and speed of storage can affect the performance of the database. Solid-state drives (SSDs) are faster than traditional hard drives, and can greatly improve the performance of read-heavy workloads.
Network: The network bandwidth and latency can affect the performance of remote clients connecting to the database server. Having a fast and low-latency network can improve the performance of remote clients.
Concurrent Connections: The amount of concurrent connections the hardware can handle will affect the overall performance. if your hardware can handle more connections than you are actually using, it will not be fully utilized and the performance will be lower.
Upgrading memory can help increase the effectiveness of data caching and allow the database to access data more quickly. Additionally, separating the application from the database can improve the performance of both, as the resources of one will not adversely affect the other. Finally, optimizing the PostgreSQL configuration file can help increase overall
3. Database Design :
Database design is a critical aspect of PostgreSQL performance as it can greatly impact the speed of queries. One key aspect of database design is the use of indexes. Indexes are used to quickly locate and retrieve data from a table. Without an index, PostgreSQL would need to scan the entire table to find the relevant data, which can be slow for large tables. There are several types of indexes available in PostgreSQL such as B-tree, Hash, GIN, and GIST indexes, each suitable for different use cases. The proper use of indexes can greatly improve the performance of queries.
Another aspect of database design that can affect query performance is the proper use of data types. Choosing the right data type for a column can greatly improve the performance of queries. For example, using an integer data type for a column that only contains whole numbers will take up less space and be faster to query than using a floating-point data type. Similarly, using a date data type for a date column will be faster than using a text data type.
Additionally, the normalization of the database is also important. Normalization is the process of organizing data in a way that eliminates data redundancy and improves data integrity. A well-normalized database can improve the performance of queries by reducing the amount of data that needs to be scanned to find the relevant information.
4. Database workload
Database workload can have a significant impact on PostgreSQL performance.
The amount of data and the number of concurrent transactions can affect the performance of PostgreSQL. A high number of concurrent transactions can lead to contention for resources such as locks and shared buffers, which can slow down performance. Additionally, a large amount of data can make it difficult for the database to find and retrieve the required information quickly.
Application workload: The way the application is designed and implemented can also impact the performance of PostgreSQL. For example, if the application is making a high number of small, simple queries, it can put a lot of pressure on the database and slow down performance.
Connection pooling: Connection pooling is a technique used to manage a large number of connections to a database. It allows a pool of connections to be shared among multiple applications, reducing the overhead of creating and closing connections. However, if the number of connections is too high, it can lead to contention for resources such as memory and CPU.
To improve the performance of PostgreSQL in these situations, it is important to monitor the database and application workloads, and adjust the configuration and design of the database and application as needed. Some tools that can help monitor the workload and performance of PostgreSQL include pgpool or PgBouncer can be used to manage connection pooling and improve performance.
5. Query optimization
Query optimization can drastically affect PostgreSQL performance by improving the efficiency of the query planning and retrieval of data from hardware. Query optimization is the process of improving the performance of SQL queries by identifying and addressing bottlenecks in the query execution process. In PostgreSQL, query optimization is performed by the query planner and optimizer, which analyze the query and generates an execution plan that is designed to minimize the cost of executing the query.
Advantages of query optimization include:
Faster query execution: Optimizing queries can greatly improve their execution time, which can lead to faster response times and improved overall performance of the database.
Reduced load on the server: Optimizing queries can also reduce the load on the server, which can help prevent performance bottlenecks and improve the scalability of the database.
Improved efficiency: Optimizing queries can lead to improved efficiency, which can help reduce resource consumption and costs.
There are several tools available to help identify and address performance bottlenecks in queries. Some common tools include:
EXPLAIN: The EXPLAIN command allows you to see the execution plan that the query planner and optimizer have generated for a query. This can help you identify which parts of the query are taking the most time and resources.
pgAdmin: pgAdmin is a popular open-source management tool for PostgreSQL that provides a graphical interface for managing and optimizing databases, including tools for analyzing and optimizing query performance.
pg_stat_statements: pg_stat_statements is a PostgreSQL extension that provides detailed statistics on query performance, including the number of times a query has been executed and the total time it has taken to execute.
pg_top: pg_top is a command-line tool that provides real-time statistics on the performance of a PostgreSQL server, including information on the most active queries and their resource usage.
6. Maintenance tasks
Regular maintenance tasks such as vacuuming and indexing are necessary for optimal performance in PostgreSQL. These tasks help to keep the database running smoothly by removing old, deleted, or unneeded data, and by updating indexes to reflect changes in the data.
Vacuuming is the process of removing old or deleted data that is no longer needed by the database. This task is important because it helps to reclaim space that is being used by dead tuples, and it also helps to improve query performance by keeping the statistics up-to-date.
Autovacuum is a built-in feature of PostgreSQL that automatically performs vacuuming in the background. Autovacuum runs in its own process, and it is designed to be lightweight so that it does not impact the performance of the database. Autovacuum is configured using a set of parameters in the PostgreSQL configuration file, such as autovacuum_vacuum_scale_factor, autovacuum_vacuum_threshold, and autovacuum_analyze_scale_factor. These parameters control the threshold at which autovacuum starts, the number of dead rows that must be present to trigger a vacuum, and the fraction of the table that must be vacuumed.
Manual vacuum is a process that is performed manually by a database administrator. The manual vacuum process is typically used to perform a full vacuum on a table, rather than the incremental vacuuming that is performed by autovacuum. Manual vacuum operations can also be performed to reclaim space from large tables that have a lot of dead rows. Manual vacuum can be executed by running the VACUUM command on a specific table or on all the tables in the database.
The choice between autovacuum and manual vacuum depends on the specific requirements of the database and the resources available. Autovacuum is generally considered to be the best option for most scenarios, as it can be configured to run at times when the load on the database is low, and it can be fine-tuned to minimize the impact on performance. However, manual vacuum can be useful for specific scenarios, such as reclaiming space from large tables or for debugging and troubleshooting purposes.
Indexing is the process of creating a data structure that allows the database to quickly find and retrieve data. In PostgreSQL, indexes are created on specific columns of a table and are used to speed up the execution of queries that filter or sort the data based on those columns.
Advantages of regular maintenance tasks:
Improved performance: Regular maintenance tasks help to keep the database running smoothly and can improve the performance of queries by keeping data and indexes up-to-date.
Reduced disk space usage: Regular vacuuming can help to reduce disk space usage by removing old, deleted, or unneeded data.
Increased data integrity: Regular maintenance tasks can help to ensure the integrity of the data by removing inconsistencies and errors.
Stay tuned for Blog-2 where we are going to dig deeper into the
Tools we can use to identify the problems
Configuration settings on the database - Key parameters to tune and how.
OS level parameter tuning.
In some use cases having a database proxy might be also beneficial for performance - https://packagemain.tech/p/the-developers-guide-to-database