
PostgreSQL locking : From 0 to 100
PostgreSQL maintain data Consistency through various type of locking. Whether you are a data architect developer, DBA or consultant - you should know all about locking, use cases, monitoring locks

Hello, and welcome to a free monthly edition of my newsletter. I’m Ajay, and each week I tackle reader questions about PostgreSQL, working and implementing PG with best practices, and anything else that’s stressing you out in the PostgreSQL world. Send me your questions and in return, I’ll humbly offer actionable real-talk advice. 🤜🤜
If you find this post valuable, check out some of my other posts:
To receive this newsletter in your inbox weekly, consider subscribing 👇

PostgreSQL is a powerful and flexible open-source relational database management system used by many organizations from startups to enterprises. However, managing concurrent access to data is one of the biggest challenges for any database system, and PostgreSQL is no exception.
That's where locking comes in…
Locking is a mechanism that PostgreSQL uses to prevent multiple transactions from simultaneously accessing the same data, which can cause data inconsistency or corruption. In really simple terms, locking ensures that database transactions are executed in a serializable order.
In this blog, we'll take a closer look at PostgreSQL's locking mechanism and explore the different types of locks that PostgreSQL supports, such as row-level locks, table-level locks, and advisory locks. We'll discuss the benefits and drawbacks of each type of lock and explore how to use them effectively to improve database performance and scalability.
So whether you're a database administrator, a developer, or just someone interested in learning more about PostgreSQL, this blog is for you!
Please keep in mind that this Blog Post is part1 of the “PostgreSQL locking : From 0 to 100” , I will publish the series on locking to ensure we are going and learning in depth with the right concepts, examples and SQL queries we can leverage for monitoring locks.
Overview and What is the need for PostgreSQL Locks
Like any other relational database management system that supports concurrency control through a variety of locking mechanisms? When multiple transactions are executed concurrently, it is essential to ensure that they do not interfere with each other, resulting in data inconsistencies or corruption. This is where locking comes in. Locks are used to prevent multiple transactions from modifying the same data simultaneously.
PostgreSQL uses a multi-version concurrency control (MVCC) framework to achieve this. This framework creates separate versions of data for each transaction so that each transaction can access a consistent and up-to-date snapshot of the data. This allows multiple transactions to access the same data simultaneously while maintaining consistency and transaction isolation.
Note: Please refer to the MVCC blog created by Hironobu SUZUKI https://www.interdb.jp/pg/pgsql05.html for detailed information. It’s one of the best available blog to learn about MVCC
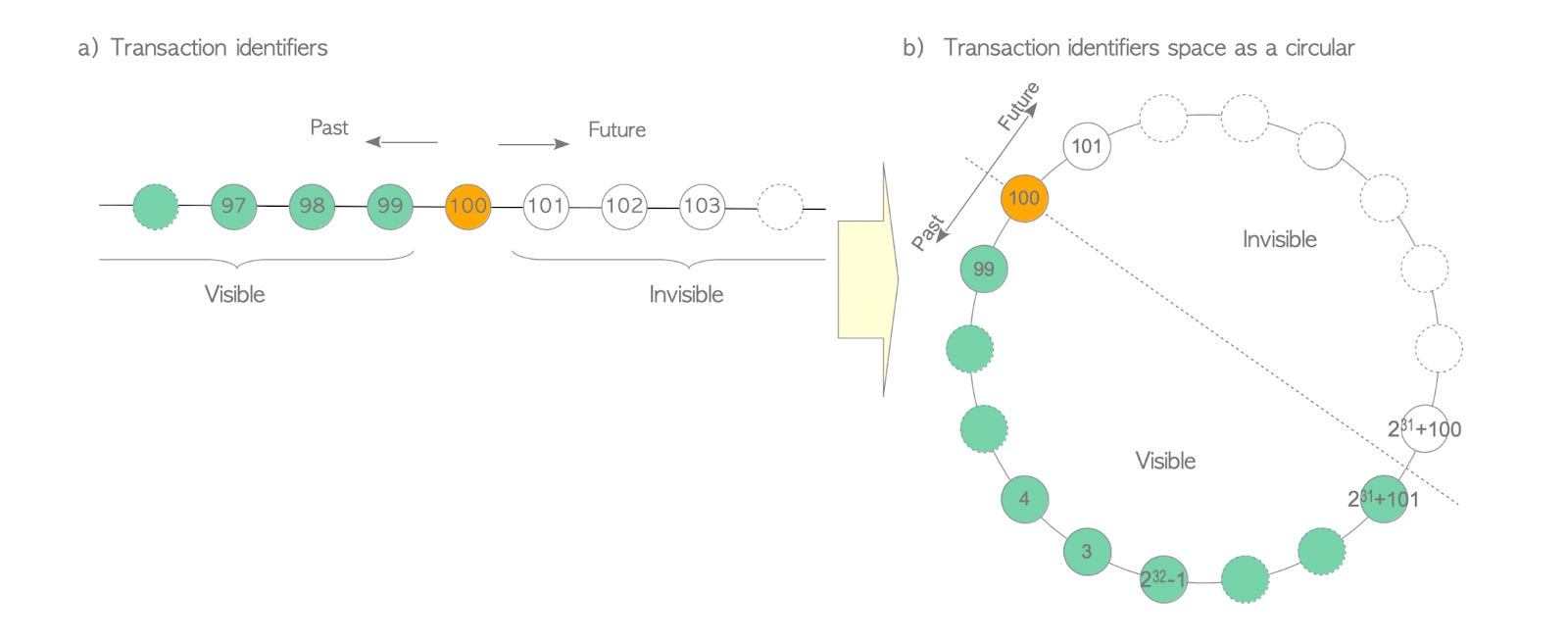
However, there are situations where conflicts can arise between transactions.
For example, if two transactions try to modify the same record simultaneously, or if one transaction tries to truncate a table while another transaction is using it. In such cases, locks are necessary to ensure that transactions are executed in a safe and consistent manner.
PostgreSQL provides various types of locks, such as shared locks and exclusive locks, to manage concurrency. By managing locks, PostgreSQL ensures that transactions are isolated from each other and executed in a safe and consistent manner, preventing data inconsistencies or corruption.
Understanding basic locking
In this section, you will learn about basic locking mechanisms. The goal is to understand how locking works in general and how to get simple applications right. To show you how things work, we will create a simple table. For demonstrative purposes, I will add one row to the table using a simple INSERT
test=# CREATE TABLE t_test (id int);
test=# INSERT INTO t_test(id) VALUES (0);
INSERT 0 1
The first important thing is that tables can be read concurrently. Many users reading the same data at the same time won't block each other. This allows PostgreSQL to handle thousands of users without any problems.
The question now is what happens if reads and writes occur at the same time? Here is an example. Let's assume that the table contains one row and its id = 0:

Two transactions are opened. The first one will change a row. However, this is not a problem as the second transaction can proceed. It will return the old row as it was before UPDATE. This behavior is called Multi-Version Concurrency Control (MVCC).
“Write transactions won't block read transactions.” . In PostgreSQL, this is absolutely not a problem—reads and writes can coexist.
What will happen if two people change data at the same time? Here is an example:

Suppose you want to count the number of hits on a website. If you run the preceding code, no hit will be lost because PostgreSQL guarantees that one UPDATE statement is performed after the other.
Types of Locks in PostgreSQL: Explanation of the various types of locks available in PostgreSQL.
PostgreSQL Locks is one of the critical topics of PostgreSQL, especially for developers who code with databases. PostgreSQL Locks help us with concurrent access or modifications of the database objects by issuing a lock as soon as the command is executed.
PostgreSQL supports three mechanisms of locking
Table Level Locks
Row Level Locks
Advisory Locks
Table level and Row-level locks can be explicit or implicit, whereas Advisory locks are explicit.
Implicit locks mean the locks would go off by default when the transaction ends.
Explicit locks once acquired may be held until explicitly released. We can acquire locks explicitly with the WITH LOCK statement.
PostgreSQL Locks: Table Level Locks
Table level locks in PostgreSQL are used to specify the mode of locking and the table name, preventing the table from being used for read or write operations. The lock modes available in PostgreSQL are
ACCESS SHARE
ROW SHARE
ROW EXCLUSIVE
SHARE UPDATE EXCLUSIVE
SHARE
SHARE ROW EXCLUSIVE
EXCLUSIVE
ACCESS EXCLUSIVE
ACCESS SHARE is used by the SELECT command and prevents any DELETE, ALTER, or vacuum commands from executing.
ROW SHARE is acquired by the writers writing an exclusive row.
ROW EXCLUSIVE is used whenever a row is deleted or updated and is acquired by the UPDATE, INSERT and DELETE commands.
SHARE UPDATE EXCLUSIVE is used to prevent any concurrent updates and is acquired by the VACUUM (without FULL), ANALYZE, CREATE INDEX CONCURRENTLY, and some forms of ALTER TABLE commands.
SHARE is used to ensure the table's stability during a transaction and is acquired by the CREATE INDEX command.
SHARE ROW EXCLUSIVE is used to hold one exclusive row in one session and is not acquired automatically.
EXCLUSIVE allows only reads to process in parallel with the transaction that acquired this lock and is not acquired implicitly by any command.
ACCESS EXCLUSIVE is the most restrictive lock mode and is used when no mode of lock is specified. It is acquired by the ALTER TABLE, DROP TABLE, TRUNCATE, REINDEX, CLUSTER, and VACUUM FULL commands.
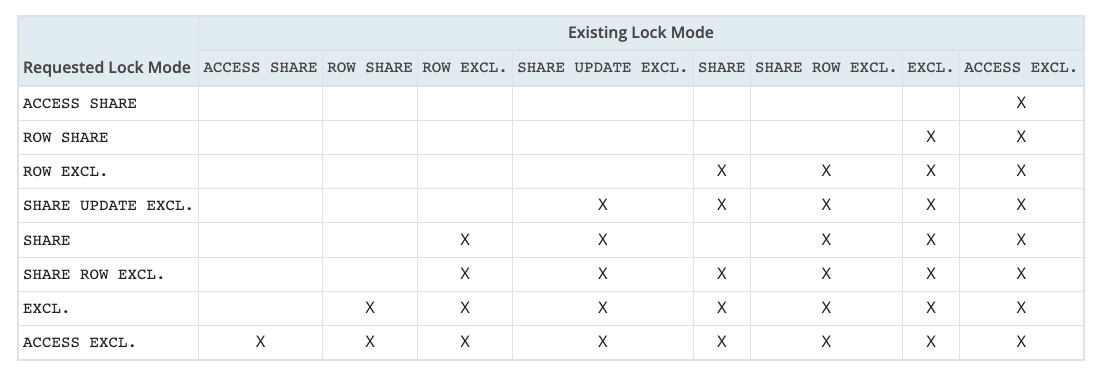
The locks are held for the duration of the current transaction after it has been achieved and are always released after a transaction; there is no UNLOCK TABLE command. The table of conflicting locks shows which modes are in conflict with each other, and transactions can’t hold locks on conflicting modes on the same table at the same time. Some lock modes are self-conflicting, and when some lock mode is acquired, it is held until the end of the transaction, but if a lock is acquired after establishing a savepoint, the lock is released immediately if the savepoint is rolled back to.
Conflicting Lock Modes
ACCESS SHARE LOCK:
"ACCESS SHARE" is the lowest level of lock mode in PostgreSQL, and it allows concurrent transactions to read a table while preventing any modifications to it. This lock mode is used when a transaction needs to read the table but does not intend to modify it.
When a transaction acquires an "ACCESS SHARE" lock on a table, other transactions can also acquire the same lock mode on the same table simultaneously. This means that multiple transactions can read the table concurrently, without blocking each other.
However, if a transaction attempts to acquire a higher level lock mode (e.g., ROW EXCLUSIVE, SHARE UPDATE EXCLUSIVE, EXCLUSIVE, or ACCESS EXCLUSIVE) on the same table, it will be blocked until the existing "ACCESS SHARE" locks are released by other transactions. This ensures that a transaction can only modify a table if no other transaction is reading or modifying the same table concurrently.
Here's an example scenario where "ACCESS SHARE" lock mode might be used:
Suppose there is an e-commerce website that allows customers to browse and purchase products online. When a customer visits the website and searches for a product, the website needs to retrieve the relevant product information from the database.
In this scenario, the transaction executing the search query would acquire an "ACCESS SHARE" lock on the table containing the product information. This lock mode would allow other transactions to concurrently read the table (e.g., display the product information on the website) but would prevent any modifications to the table (e.g., updating the product information).
By using "ACCESS SHARE" lock mode, the website can ensure that multiple customers can search for products and view product information concurrently without causing conflicts or blocking each other.
CREATE TABLE employees ( id serial primary key, name varchar(50), department varchar(50), salary numeric(10,2) );session 1 which acquires Access Share Lock
begin;
SELECT *, pg_sleep(300) from employees;session 2
begin;
TRUNCATE TABLE employees;
As you can see Session 1 acquired AccessShareLock to fetch the records.
To truncate a table session 2 has to acquire a lock with a mode AccessExclusiveLock but is waiting to acquire it because of lock conflict.
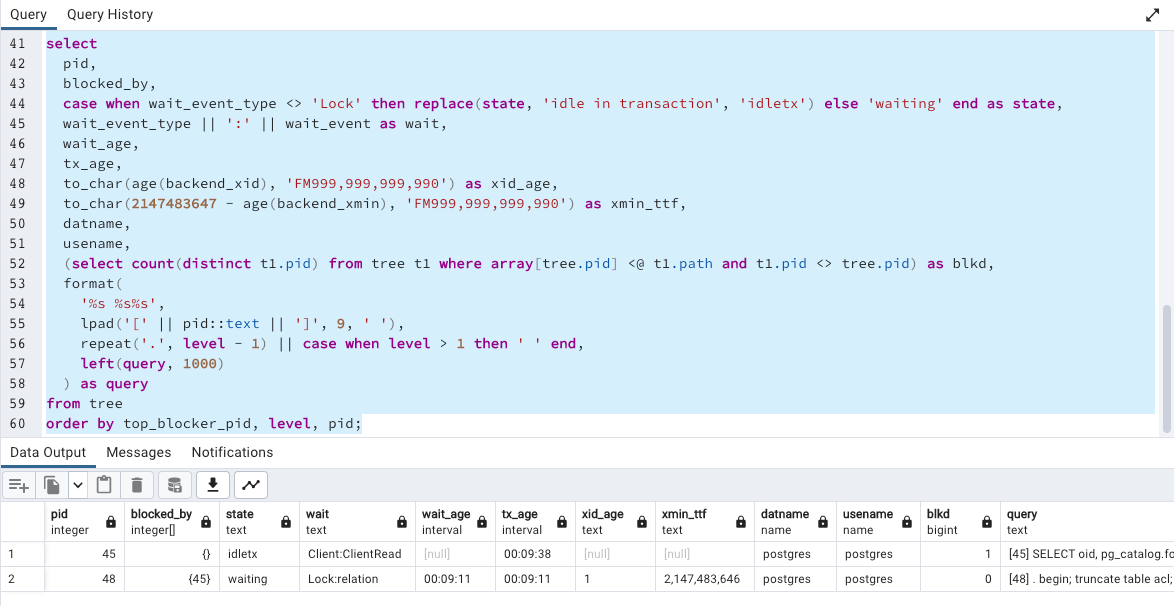
with recursive activity as (
select
pg_blocking_pids(pid) blocked_by,
*,
age(clock_timestamp(), xact_start)::interval(0) as tx_age,
-- "pg_locks.waitstart" – PG14+ only; for older versions: age(clock_timestamp(), state_change) as wait_age
age(clock_timestamp(), (select max(l.waitstart) from pg_locks l where a.pid = l.pid))::interval(0) as wait_age
from pg_stat_activity a
where state is distinct from 'idle'
), blockers as (
select
array_agg(distinct c order by c) as pids
from (
select unnest(blocked_by)
from activity
) as dt(c)
), tree as (
select
activity.*,
1 as level,
activity.pid as top_blocker_pid,
array[activity.pid] as path,
array[activity.pid]::int[] as all_blockers_above
from activity, blockers
where
array[pid] <@ blockers.pids
and blocked_by = '{}'::int[]
union all
select
activity.*,
tree.level + 1 as level,
tree.top_blocker_pid,
path || array[activity.pid] as path,
tree.all_blockers_above || array_agg(activity.pid) over () as all_blockers_above
from activity, tree
where
not array[activity.pid] <@ tree.all_blockers_above
and activity.blocked_by <> '{}'::int[]
and activity.blocked_by <@ tree.all_blockers_above
)
select
pid,
blocked_by,
case when wait_event_type <> 'Lock' then replace(state, 'idle in transaction', 'idletx') else 'waiting' end as state,
wait_event_type || ':' || wait_event as wait,
wait_age,
tx_age,
to_char(age(backend_xid), 'FM999,999,999,990') as xid_age,
to_char(2147483647 - age(backend_xmin), 'FM999,999,999,990') as xmin_ttf,
datname,
usename,
(select count(distinct t1.pid) from tree t1 where array[tree.pid] <@ t1.path and t1.pid <> tree.pid) as blkd,
format(
'%s %s%s',
lpad('[' || pid::text || ']', 9, ' '),
repeat('.', level - 1) || case when level > 1 then ' ' end,
left(query, 1000)
) as query
from tree
order by top_blocker_pid, level, pid;
I hope you have learned something new today. In Part 2 onwards we will cover the rest of the Lock types with more examples.
keep learning