
Data in Motion: The 7 Foundational Shifts Powering AI-Native platforms
The rise of semantic data, hybrid stores, and the convergence of analytics + intelligence.


The Quiet Revolution Beneath AI
Artificial Intelligence is getting all the spotlight , but the true transformation and magic hallens on the backend and platform layer — deep within the data layer.
Over the past decade, we’ve evolved from collecting data to connecting it. AI has shifted expectations: it doesn’t just need more data; it needs smarter, faster, and more context-aware data systems.
Traditional warehouses and dashboards were built for a world of human analysts. But AI demands something else entirely continuous, connected, and semantically rich data that can flow through models in real time.
This is the story of seven foundational shifts that are quietly redefining modern architectures, these 7 shifts are the the building blocks of AI-native data ecosystems.

📖 Reference: McKinsey – The data architecture needed for AI
Shift #1: From Static Data Warehouses → Dynamic Data Lakes
For decades, enterprises relied on data warehouses — centralized, structured systems optimized for queries, reports, and dashboards. These worked well when business data was neat: transactions, orders, and logs that changed slowly.
But the AI era has changed that equation entirely.
Today, data is born fast, messy, and continuous — streaming in from sensors, user interactions, APIs, and machine outputs in formats that SQL alone can’t tame.
The traditional warehouse model — batch ETL into static schema — can’t keep up with AI’s appetite for real-time, multimodal data.
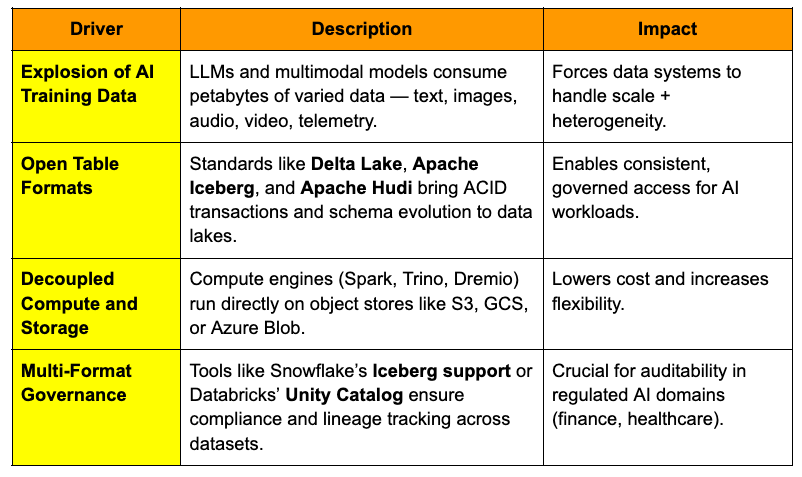
That’s why organizations are rapidly moving toward dynamic, open data lakes and lakehouses — hybrid architectures designed to unify structured, semi-structured, and unstructured data under one roof.
What Changed
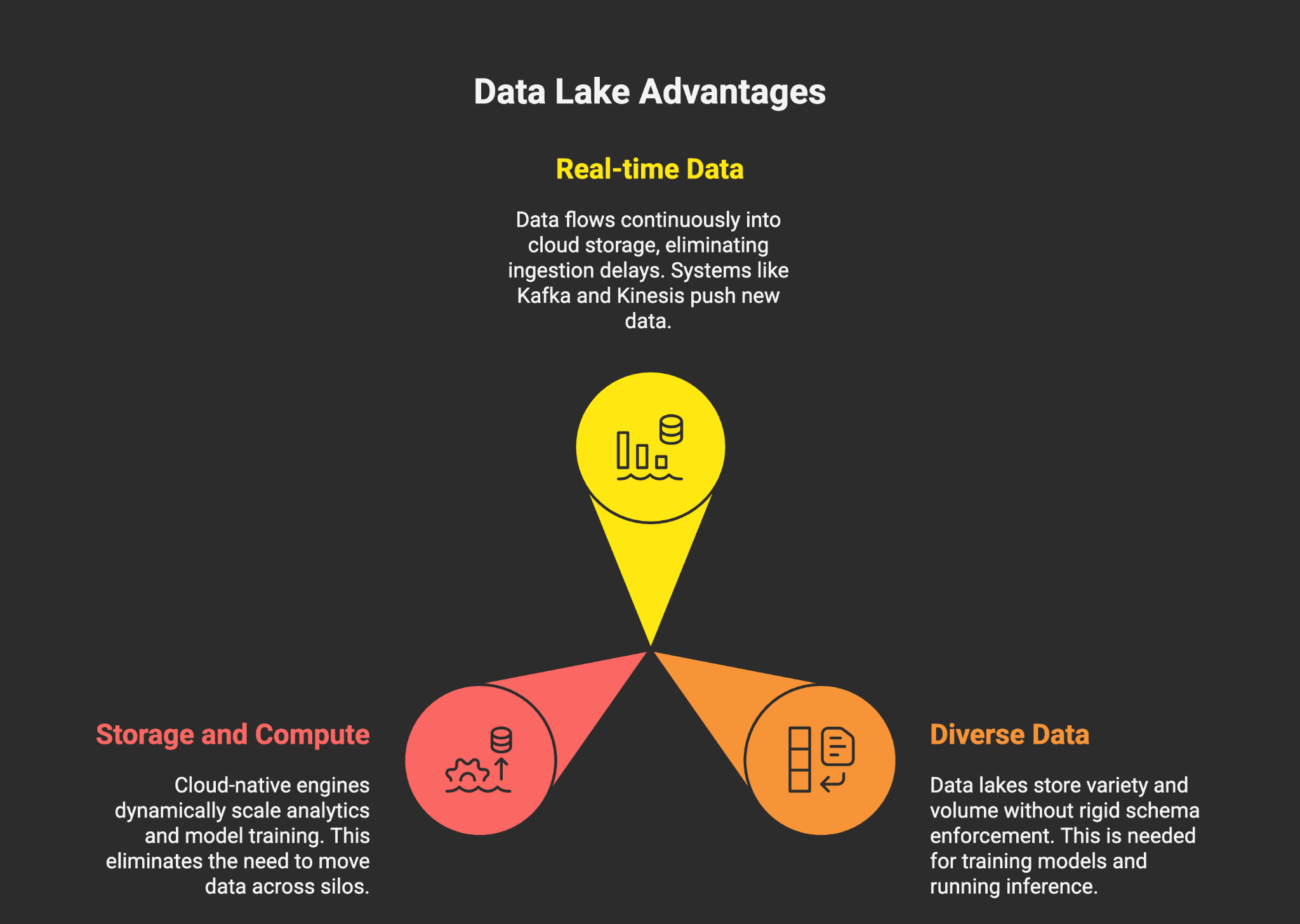
1. Data Is No Longer Batched — It’s in Motion
The rise of streaming pipelines and event-driven architectures means data doesn’t wait for overnight ETL. It flows continuously into cloud storage and is made queryable in near real time.
Systems like Apache Kafka, Kinesis, and Databricks Auto Loader continuously push new data into these lake environments, eliminating manual ingestion delays.
2. AI Needs All Data, Not Just Clean Data
Training a model or running inference requires diversity: text for embeddings, logs for anomaly detection, audio for transcription, video for vision tasks, and tabular data for features.
Data lakes — unlike warehouses — can store this variety and volume without rigid schema enforcement.
3. Convergence of Storage and Compute
Modern architectures separate compute from storage, but orchestrate them dynamically. Cloud-native engines (e.g., Databricks Photon, Snowflake Polaris) spin up workloads as needed, scaling analytics and model training without moving data across silos.
Key Drivers Behind the Shift
References reads
Databricks Lakehouse Architecture: https://www.databricks.com/product/data-lakehouse
Apache Iceberg Documentation: https://iceberg.apache.org/docs/latest/
Apache Hudi Documentation: https://hudi.apache.org/docs/
Why It Matters for AI
AI models , whether large-scale transformers or domain-specific classifiers thrive on context and diversity. They require a constant stream of updated data, not static snapshots. Static ETL pipelines introduce latency and bias: a model trained on last month’s data might already be outdated.
Dynamic data lakes enable:
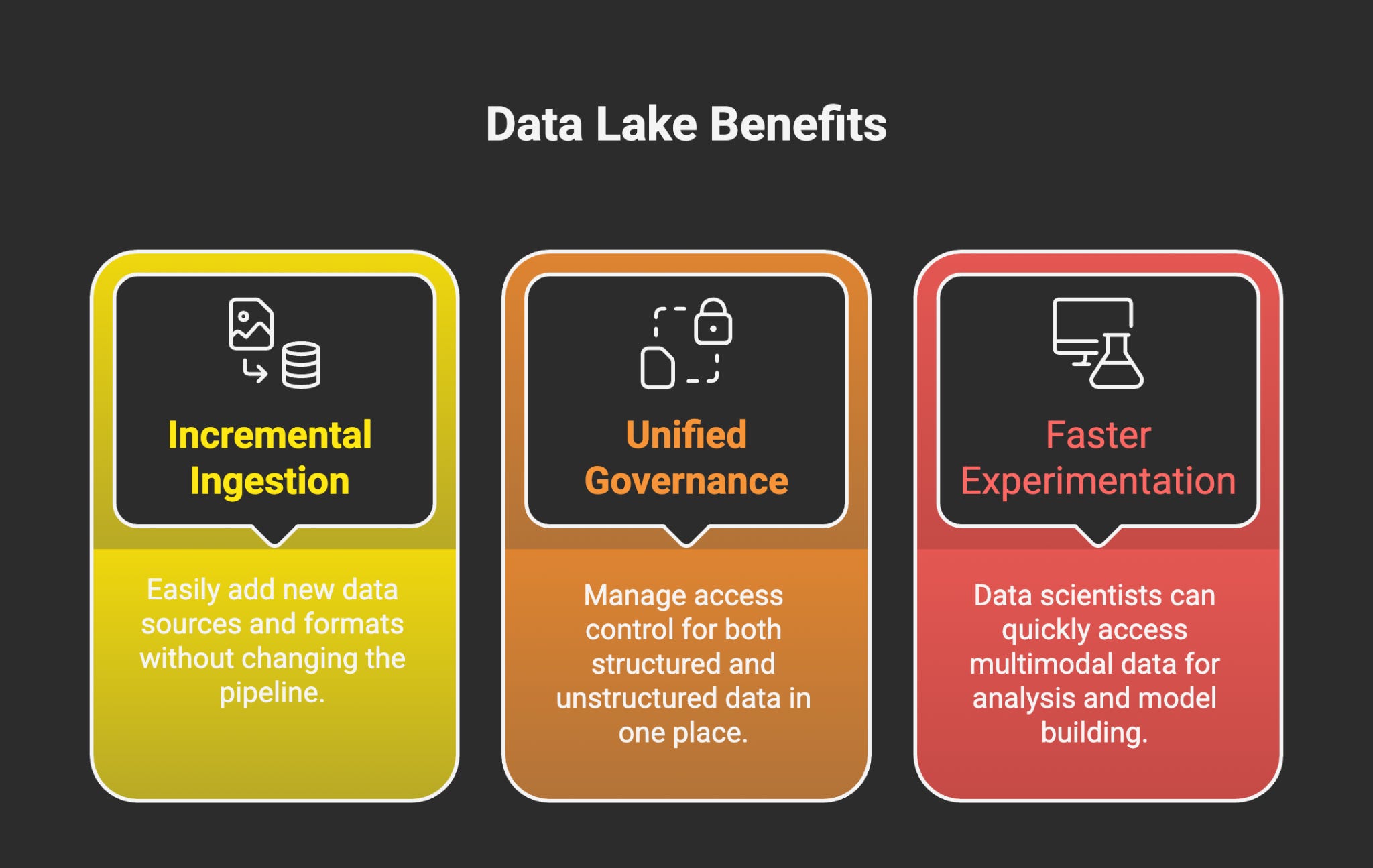
Incremental ingestion and schema evolution — new columns, new formats, or new data sources without pipeline rewrites.
Unified governance across structured and unstructured data — ensuring both your transaction logs and PDF documents share a single access control layer.
Faster experimentation cycles — data scientists can pull multimodal data directly into notebooks or AutoML systems, without waiting for DBA approval.
In short, the lakehouse model becomes the foundation of continuous learning, where models and data evolve together.
Real-World Examples
1. Databricks Delta Lake – Unified Analytics for ML and AI
Provides ACID transactions and time-travel capabilities on top of raw data lakes.
Enables batch + streaming under one storage layer using Delta tables.
At Shell and Comcast, Databricks reported 50% faster time-to-insight and 40% reduction in data duplication after migrating to lakehouse architecture.
2. Snowflake with Apache Iceberg – Multi-Format Governance
Snowflake’s integration with Apache Iceberg allows external table access on S3 without data copying.
Enterprises can manage Delta, Iceberg, and Parquet data through a unified governance layer.
This dramatically reduces duplication and improves compliance visibility.
3. Uber’s OneLake Initiative
Consolidated 100+ petabytes of data into a single internal lake built on HDFS + Iceberg.
Powers real-time feature computation for recommendation and pricing models.
Resulted in 70% faster data availability for model retraining and experimentation.
Use Case: AI-Powered Fraud Detection
A global fintech company collecting billions of transactions per day uses a Delta Lake architecture to power its fraud detection models.
Each transaction event flows through Kafka into the data lake within seconds.
ML pipelines built in Databricks consume this live data to retrain classifiers hourly, improving detection rates and reducing false positives by over 30%.
This use case is a hallmark of why static warehouses fail — fraud patterns evolve daily, and AI defenses need equally dynamic data access.
🔍 Takeaway
The transition from static warehouses to dynamic lakes isn’t just an architectural upgrade — it’s a philosophical shift: from data as something you store, to data as something that lives, evolves, and fuels intelligence.
In AI-native organizations, data lakes are no longer the backend.
They are the lifeblood of learning systems, continuously feeding the next generation of models that will define competitive advantage.
“In the world of AI, a lake that doesn’t move becomes a swamp.”